机器学习之聚类学习 2024-05-18 学习, 支持向量机, 聚类, 机器学习, 人工智能 179人 已看 根据每个类别样本点,重新计算出新聚类中心点(平均值),若计算出的新中心与原中心点重叠,则停止聚类,否重新进行第2步过程,直到聚类中心不再变化。在决定什么时候停止训练时,肘形判断同样有效,数据通常有更多噪音,在增加分类无法带来更多汇报时,即停止增加类别。,将样本划分到不同类别种,不同相似度计算方法,会得到不同聚类结果,常用相似度计算方法为:欧氏距离。对于n个数据集,迭代计算k from i to n,每次聚类完成后计算SSE。整型状,缺省值=8,生成聚类数,即产生质心(centroids)数。
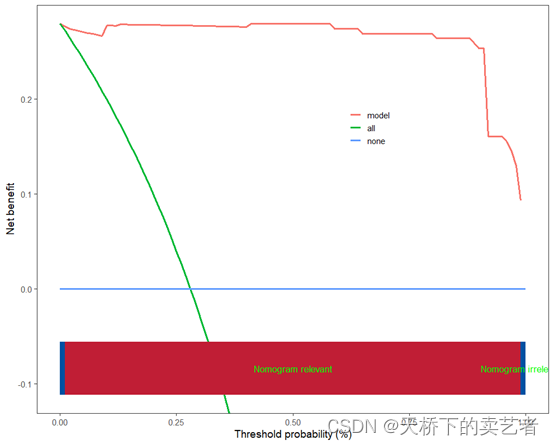
R语言使用 ggscidca包优雅的绘制支持向量机决策曲线 2024-05-17 算法, 支持向量机, 机器学习, r语言, 开发语言 108人 已看 数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,BMI肥胖指数,FEV1肺活量指标,WEIGHT体重,“SBP”,“DBP”:收缩压和舒张压。进行分析前还需对数据进行预处理,如果你是多分类的,并且数据差异大,可以使用分层抽样,尽量是数据匹配一下,方法详见我既往文章《R语言两种方法实现随机分层抽样》,我这里是二分类,我就不弄了。最后向大家汇报一下,多模型的决策曲线和混合模型的决策曲线已经写好,下周上传,到时我再出个视频介绍一下。定义一个标准化的小程序。
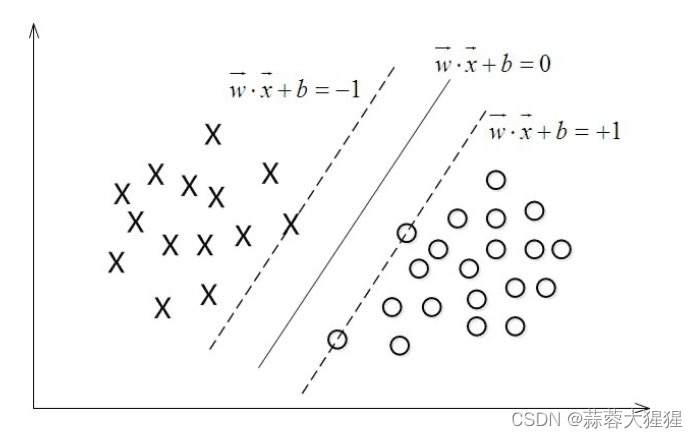
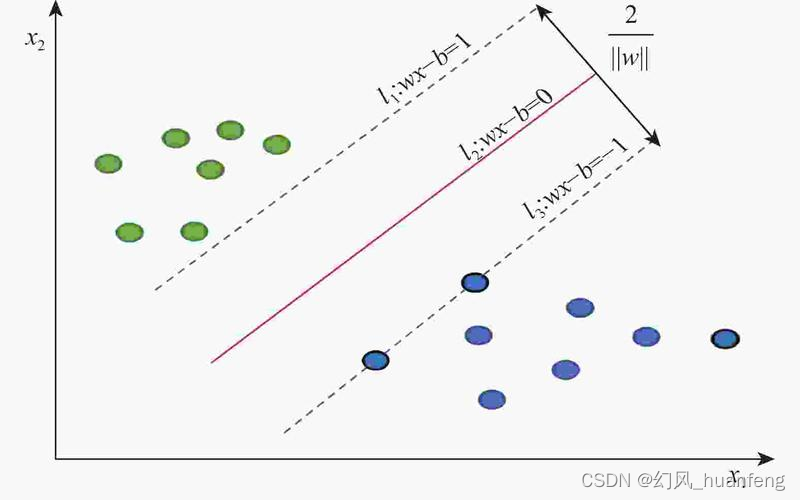
超简单白话文机器学习 - 支持向量机SVM(含算法讲解,公式全解,手写代码实现,调包实现) 2024-05-21 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 193人 已看 支持向量机,因其英文名为supportvectormachine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
机器学习------聚类 2024-05-17 算法, 支持向量机, 聚类, 机器学习, 人工智能 181人 已看 在聚类算法中根据样本之间的相似性,将样本互粉到不同的类别中,对于不同的相似计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别。2.计算每一个样本i到最近簇j内的所有样本的平均距离bij,该值越大,说明该样本越不属于其他簇j。1.计算每一个样本 i 到同簇内其他样本的平均距离ai, 该值越小,说明簇内的相似程度越大。整形,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
R语言使用 ggscidca包优雅的绘制支持向量机决策曲线 2024-05-17 算法, 支持向量机, 机器学习, r语言, 开发语言 116人 已看 数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,BMI肥胖指数,FEV1肺活量指标,WEIGHT体重,“SBP”,“DBP”:收缩压和舒张压。进行分析前还需对数据进行预处理,如果你是多分类的,并且数据差异大,可以使用分层抽样,尽量是数据匹配一下,方法详见我既往文章《R语言两种方法实现随机分层抽样》,我这里是二分类,我就不弄了。最后向大家汇报一下,多模型的决策曲线和混合模型的决策曲线已经写好,下周上传,到时我再出个视频介绍一下。定义一个标准化的小程序。
R语言使用 ggscidca包优雅的绘制支持向量机决策曲线 2024-05-17 算法, 支持向量机, 机器学习, r语言, 开发语言 160人 已看 数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,BMI肥胖指数,FEV1肺活量指标,WEIGHT体重,“SBP”,“DBP”:收缩压和舒张压。进行分析前还需对数据进行预处理,如果你是多分类的,并且数据差异大,可以使用分层抽样,尽量是数据匹配一下,方法详见我既往文章《R语言两种方法实现随机分层抽样》,我这里是二分类,我就不弄了。最后向大家汇报一下,多模型的决策曲线和混合模型的决策曲线已经写好,下周上传,到时我再出个视频介绍一下。定义一个标准化的小程序。
【机器学习与实现】支持向量机SVM 2024-05-20 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 114人 已看 本文介绍机器学习的支持向量机SVM,包括硬间隔、软间隔、核函数和scikit-learn中的SVM分类器及其主要参数。
[机器学习聚类算法实战-1] | Scikit-Learn工具包进阶指南:机器学习聚类算法之层次聚类、特征集聚、均值移位聚类、k-均值聚类实战分析 2024-05-16 支持向量机, 聚类, 机器学习, scikit-learn, 均值算法 227人 已看 机器学习中的聚类分析是一种无监督学习方法,旨在将数据点划分为相似的组或簇,使得同一组内的数据点彼此相似,而不同组之间的数据点则相对较不相似。聚类分析可以帮助我们理解数据的内在结构,发现数据中隐藏的模式,并将数据进行自然的分组,从而为进一步分析或决策提供基础。K-Means 聚类:将数据点分成预先指定的 k 个簇,每个簇具有最小化簇内平方误差的中心点。K-Means 是一种迭代算法,通过不断更新簇中心点来优化聚类结果。层次聚类:逐步将数据点合并到不断增长的聚类中,形成层次结构。
探索支持向量机中样本点的三重角色 2024-05-16 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 97人 已看 其次,边界向量还能够提高模型的鲁棒性。在实际应用中,我们经常会遇到一些特殊的样本点,它们可能具有特殊的性质或特征,但却不位于分类边界上。虽然非支持向量在SVM的决策过程中不直接发挥作用,但它们在模型的训练和评估过程中却具有不可忽视的作用。在这个过程中,样本点的作用举足轻重,它们扮演着三种不同的角色,共同构筑了SVM的坚实基石。在SVM中,除了支持向量和边界向量外,其余的样本点被称为非支持向量。这意味着当新的样本点出现时,SVM能够利用这些已知的支持向量来做出准确的分类决策,从而实现对新数据的良好适应。
机器学习 - 支持向量机的推导 2024-05-18 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 87人 已看 支持向量机通过找到一个最佳的超平面来分类数据,在线性可分的情况下,通过最大化间隔来确定最佳的超平面。在非线性可分的情况下,通过引入软间隔和核技巧,使得SVM可以处理更复杂的数据集。最终的优化问题可以通过求解一个二次规划问题来完成。
机器学习之支持向量机SVM 2024-05-21 算法, 支持向量机, 机器学习, 人工智能, 数据挖掘 99人 已看 gamama:值越大,高斯分布越窄(数据变化越剧烈,易过拟合),反之,值越小,高斯分布越宽(数据变化越平缓),易欠拟合,rbf是高斯核。若想找到具有最大间隔划分超平面,也就是要找到能满右足式中约束参数w和b,使得间隔γ最大。C值越大,间隔越小,落在间隔中的违例越少,反之,C值越小,间隔越大,违例越多。允许部分样本,在最大间隔之间,甚至在错误的一边,寻找最大间隔,即软间隔。将原始输入空间映射到新的特征空间,使得原本线性不可分样本在核空间可分。若样本线性可分,且所有样本分类正确情况下,寻找最大间隔,即硬间隔。
K-means聚类模型:深入解析与应用指南 2024-05-12 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 99人 已看 K-means聚类是一种广泛使用的无监督学习算法,它通过迭代过程将数据集划分为K个聚类。以下是一篇关于K-means聚类模型的技术文章,将从不同的角度进行详尽的描述。
机器学习_KNN算法 2024-05-06 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 149人 已看 K-近邻(K-Nearest Neighbors,简称KNN)算法是一种基本的机器学习分类和回归算法其核心思想是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
机器学习_朴素贝叶斯 2024-05-08 支持向量机, 算法, 机器学习, 人工智能, 数据挖掘 157人 已看 朴素贝叶斯算法(Naive Bayes Algorithm)是一种基于贝叶斯定理与特征条件独立假设的分类方法。该算法假设给定目标值时,各个特征之间相互独立。朴素贝叶斯算法通过训练数据集学习联合概率分布,并基于此模型,对给定的输入实例,利用贝叶斯定理求出后验概率最大的输出。具体来说,朴素贝叶斯算法的核心思想是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。