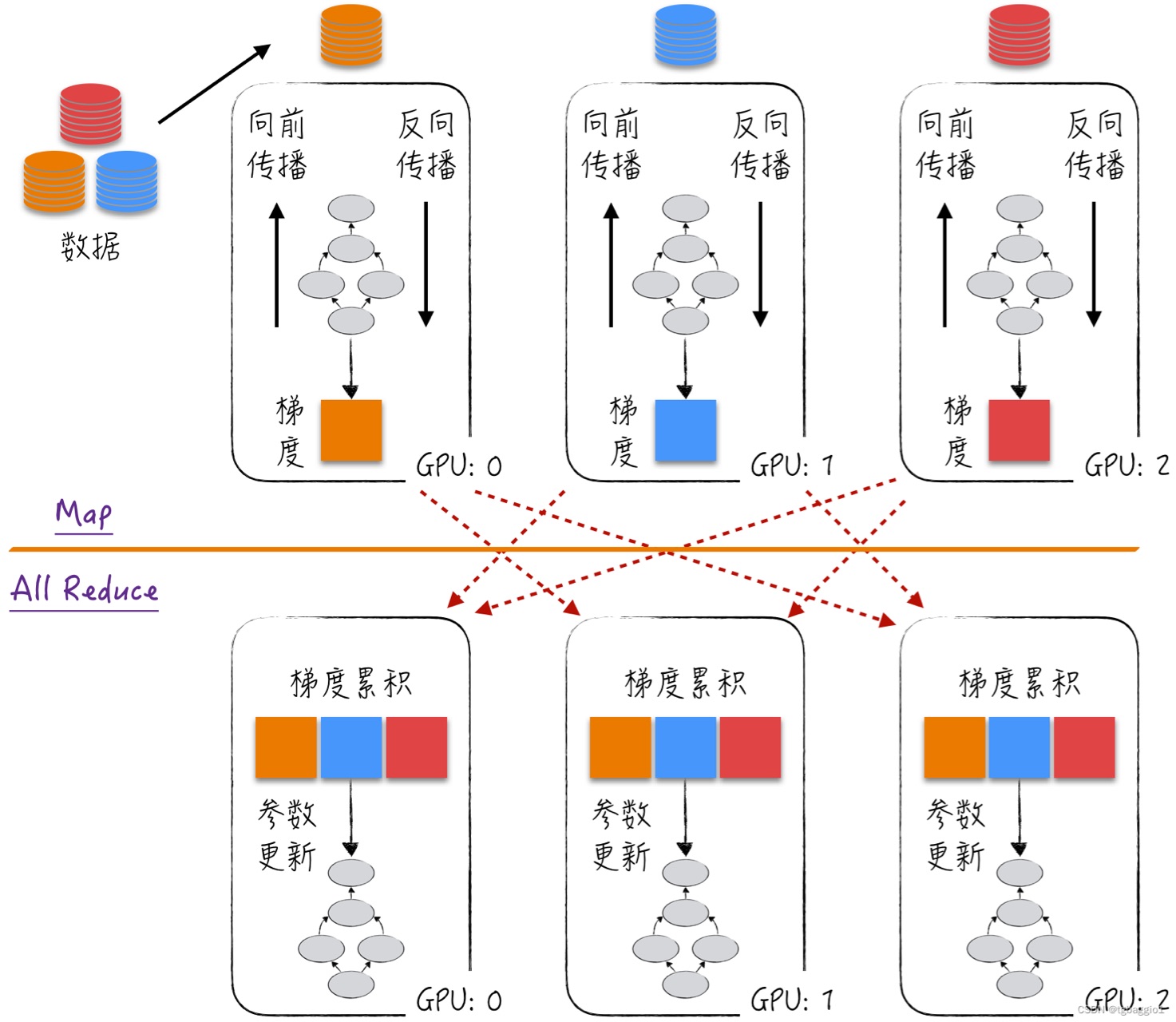
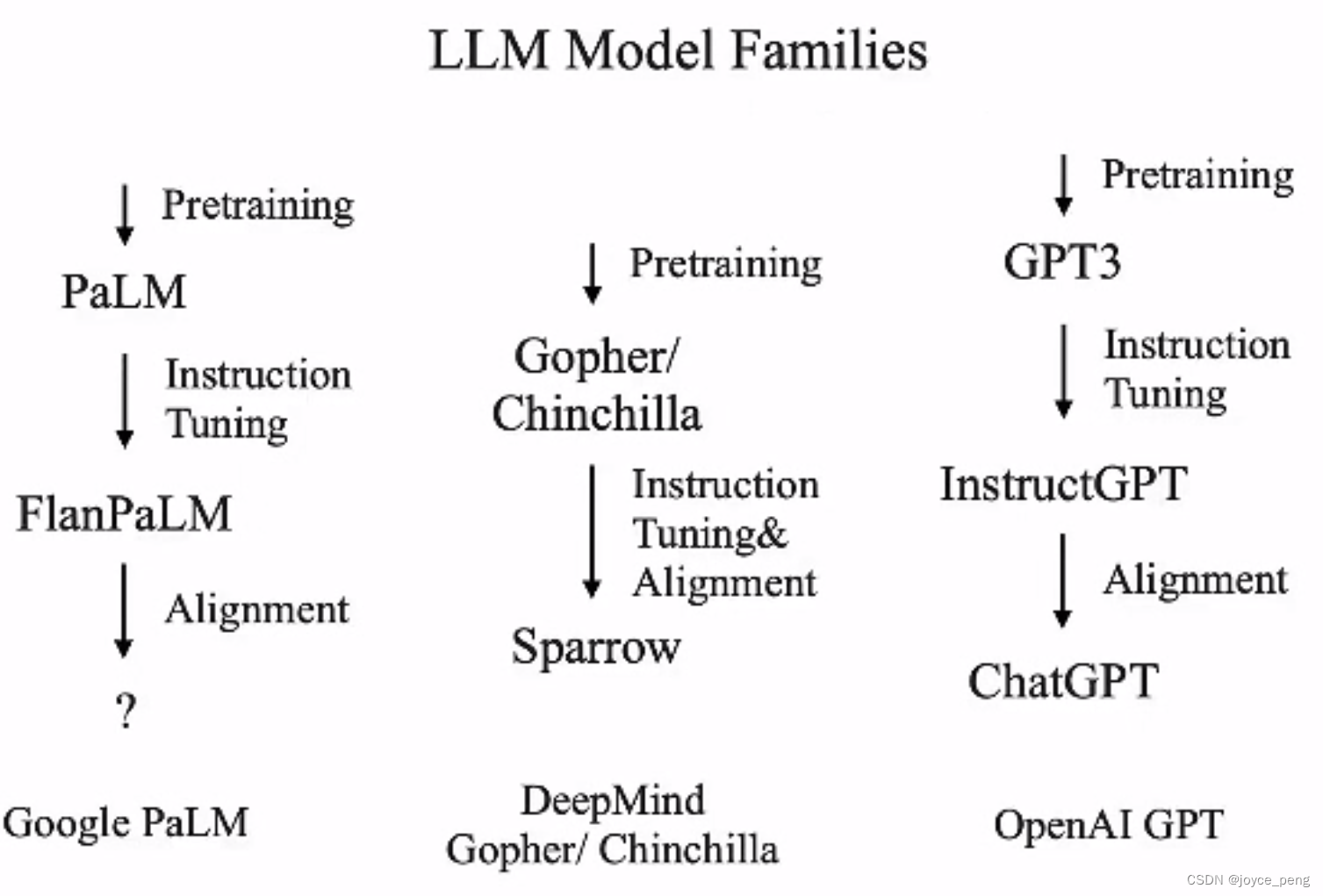
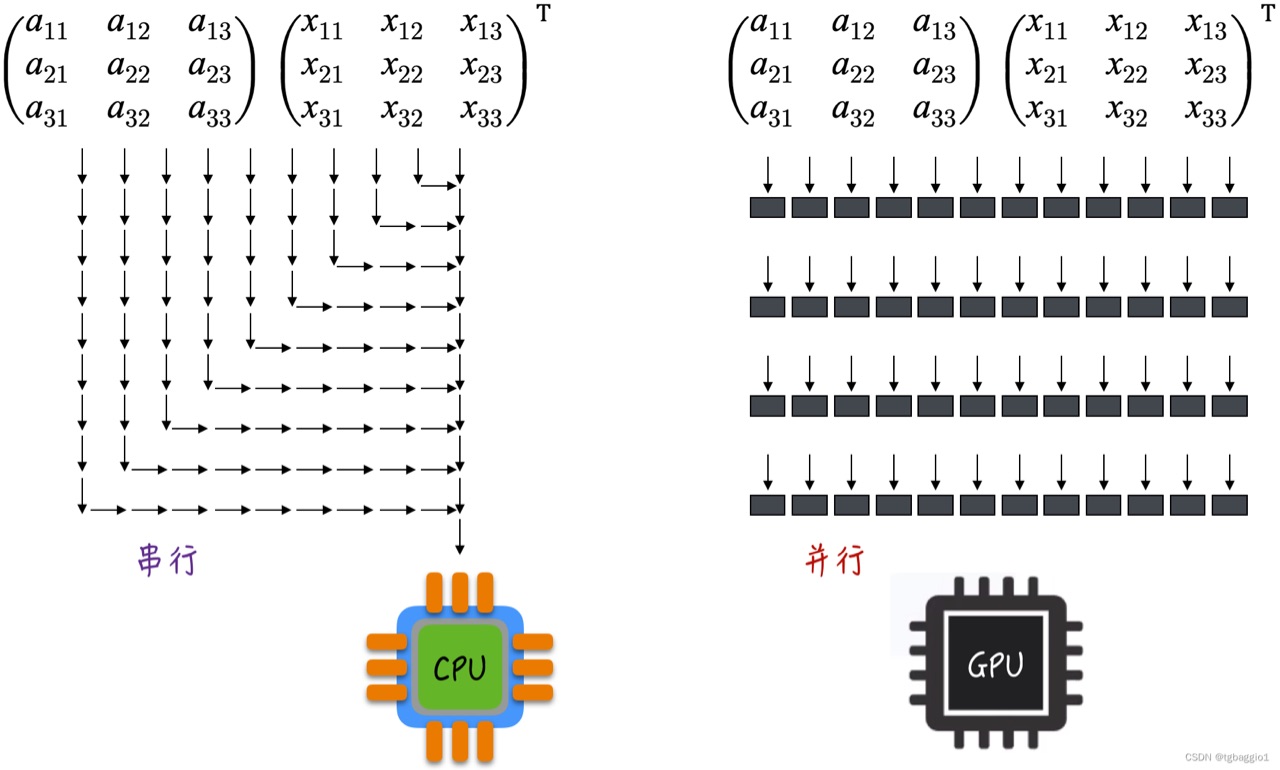
GPT-3:自然语言处理的预训练模型 2024-05-23 gpt-3, 人工智能, 自然语言处理 93人 已看 GPT-3作为当前最先进的NLP预训练模型之一,展示了强大的语言生成和理解能力。尽管其应用面临一定的挑战,但其带来的创新和可能性不可忽视。随着技术的不断进步,GPT-3及其后续版本必将在更多领域中发挥重要作用,推动人机交互和自然语言处理的进一步发展。
大型语言模型现状发展分析 2024-05-18 语言模型, 人工智能, 自然语言处理 141人 已看 大型语言模型(Large Language Models,简称LLMs)是一类使用深度学习技术训练的自然语言处理(NLP)模型,它们在大量的文本数据上进行训练,以理解和生成人类语言。这些模型通常具有数亿甚至数千亿个参数,使它们能够捕捉到语言的复杂性和细微差别。
[论文笔记]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 2024-05-21 论文阅读, 语言模型, 人工智能, 自然语言处理, prompt 171人 已看 ⭐ 思维链轮笔记:作者提出了通过生成一系列中间推理步骤的思维链,可以显著提升大型语言模型在进行复杂推理时的能力,但是仅限于100B以上的大模型。
[论文笔记]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 2024-05-21 论文阅读, 语言模型, 人工智能, 自然语言处理, prompt 149人 已看 ⭐ 思维链轮笔记:作者提出了通过生成一系列中间推理步骤的思维链,可以显著提升大型语言模型在进行复杂推理时的能力,但是仅限于100B以上的大模型。
从BERT到GPT-4:Transformer模型的进化之路与未来展望 2024-05-17 深度学习, 人工智能, gpt, 自然语言处理, bert 187人 已看 Transformer模型自2017年提出以来,已成为自然语言处理领域中最为重要和广泛使用的模型架构之一。其基于自注意力机制(Self-Attention)的设计,能够有效地捕捉文本中的长距离依赖关系,并在并行计算方面具有显著优势。Transformer模型的核心思想是利用自注意力机制来计算序列中各个位置之间的依赖关系。具体而言,对于输入序列中的每个位置,Transformer模型会计算其与其他所有位置的注意力权重,然后根据这些权重对位置进行加权求和,得到该位置的表示。Attention。
2024-05-20 问AI:介绍一下大语言模型的in-context learning 2024-05-20 语言模型, 人工智能, 自然语言处理 128人 已看 然而,ICL也面临着一些挑战,例如如何选择合适的示例、如何评估模型的性能以及如何提高模型的泛化能力等。小样本学习则是为了学习到最佳模型参数,仍然需要使用少量的监督样本做微调,而 ICL 则不对模型做任何的微调,直接将下游任务的输入输出拼接起来作为一个 prompt,引导模型根据输入的测试集样本 demo,给出任务的预测结果。总的来说,大语言模型的in-context learning是指模型在特定上下文中学习、理解和处理语言的能力,这使得模型能够更好地适应各种语言任务,并生成更准确、相关和连贯的语言输出。
视觉语言模型详解【VLM】 2024-05-20 语言模型, 人工智能, 自然语言处理 131人 已看 视觉语言模型被广泛定义为可以从图像和文本中学习的多模态模型。它们是一种生成式模型,可以接受图像和文本输入并生成文本输出。大型视觉语言模型具有良好的零样本能力,具有良好的泛化能力,并且可以处理多种类型的图像,包括文档、网页等。用例包括谈论图像、通过指令进行图像识别、视觉问答、文档理解、图像字幕等。一些视觉语言模型还可以捕获图像中的空间属性。当系统提示检测或分割特定主题时,这些模型可以输出边界框或分割掩码,也可以定位不同的实体或回答有关其相对或绝对位置的问题。
ROCm上运行自然语言推断:微调BERT 2024-05-17 深度学习, pytorch, 人工智能, 自然语言处理, bert 187人 已看 SNLIBERTDataset类处理SNLI数据库的数据,用于BERT的使用,分词数据集中的前提和假设,并创建相应的令牌ID和段ID作为模型的输入。- 使用`d2l`的`train_ch13`函数来训练模型,传入定义的网络、训练和测试迭代器、损失函数、训练器、训练周期数和设备配置。10. 使用定义的训练迭代器、损失函数、优化器以及`d2l`提供的训练工具来对SNLI数据库中的BERT分类器模型进行训练。2. 从指定的`d2l.DATA_HUB`下载预训练模型(BERT基础版和BERT小型版)。
基于大语言模型的应用 2024-05-17 语言模型, 人工智能, 自然语言处理 110人 已看 在AI领域,大语言模型已成为备受瞩目的焦点,尤其在自然语言处理(NLP)领域,其应用愈发广泛。BLM作为一种多任务语言建模方法,旨在构建一个具备多功能的强大模型。在给定文本和查询条件下,该模型能够充分利用上下文中的丰富信息,如查询内容、特定任务或领域知识,以生成准确而恰当的答案。这一特性使得BLM在优化自然语言处理任务中展现出巨大潜力。
NLP预训练模型-GPT-3:探索语言生成的新时代 2024-05-20 gpt-3, 人工智能, 自然语言处理 96人 已看 自然语言处理(NLP)领域的发展日新月异,而预训练模型已成为近年来NLP领域的热门话题之一。其中,GPT-3(Generative Pre-trained Transformer 3)作为最新一代的预训练模型,引起了广泛的关注和讨论。本文将深入探讨GPT-3的基本原理、技术特点以及应用场景,带领读者一起探索语言生成的新时代。
NLP预训练模型-GPT-3:探索语言生成的新时代 2024-05-20 gpt-3, 人工智能, 自然语言处理 102人 已看 自然语言处理(NLP)领域的发展日新月异,而预训练模型已成为近年来NLP领域的热门话题之一。其中,GPT-3(Generative Pre-trained Transformer 3)作为最新一代的预训练模型,引起了广泛的关注和讨论。本文将深入探讨GPT-3的基本原理、技术特点以及应用场景,带领读者一起探索语言生成的新时代。
基于大语言模型的应用 2024-05-17 语言模型, 人工智能, 自然语言处理 144人 已看 在AI领域,大语言模型已成为备受瞩目的焦点,尤其在自然语言处理(NLP)领域,其应用愈发广泛。BLM作为一种多任务语言建模方法,旨在构建一个具备多功能的强大模型。在给定文本和查询条件下,该模型能够充分利用上下文中的丰富信息,如查询内容、特定任务或领域知识,以生成准确而恰当的答案。这一特性使得BLM在优化自然语言处理任务中展现出巨大潜力。
大语言模型下的JSON数据格式交互 2024-05-23 语言模型, 交互, 人工智能, 自然语言处理, 搜索引擎 179人 已看 程序员或多或少要了解些人工智能,前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家(坚持不懈,越努力越幸运,大家一起学习鸭~~~随着大语言模型能力的增强,传统应用不可避免的需要调用LLM接口,提升应用的智能程度和用户体验,但是一般来说大语言模型的输出都是字符串,除了个别厂商支持JSON Mode,或者使用function call强制大语言模型输出json格式,大部分情况下,还是需要业务放自己去处理JSON格式,下面我来总结一下在解析JSON过程中遇到的一些问题和解决方案。
PaliGemma视觉语言模型综合指南 2024-05-19 语言模型, 人工智能, 自然语言处理 291人 已看 PaliGemma 与其他产品一起在 2024 年 Google I/O 活动上发布,它是一种基于 Google 研究的另外两个模型的组合多模态模型:视觉模型 SigLIP 和大型语言模型 Gemma,这意味着该模型是 Transformer 解码器和 Vision Transformer 图像编码器的组合。它将图像和文本作为输入,并生成文本作为输出,支持多种语言。相对较小的 30 亿组合参数模型允许的商业使用条款能够针对图像和短视频字幕、视觉问答、文本阅读、对象检测和对象分割进行微调。
jiebaNET中文分词器 2024-05-15 中文分词, 人工智能, 自然语言处理 99人 已看 ieba.NET分词器是一款基于.NET平台的中文分词工具,它借鉴了jieba分词器的算法和思路,为.NET开发者提供了高效、准确的中文分词功能。中文分词:jieba.NET分词器能够将中文文本按照词语进行切分,使得文本更易于被处理和分析。分词是中文文本处理的基础步骤,对于词频统计、文本分类、情感分析等任务具有重要意义。多种分词模式:jieba.NET分词器支持多种分词模式,包括精确模式、全模式和搜索引擎模式。精确模式会将句子最精确地切分开,适合在文本分析时使用;
NLP预训练模型-GPT-3 2024-05-19 gpt-3, 人工智能, 自然语言处理 115人 已看 与前两代GPT模型相比,GPT-3具有更大的模型规模(参数量达到1750亿个),更强的计算能力(使用了NVIDIA V100 GPU集群)和更广泛的数据来源(包括书籍、网页、论坛等多种类型的文本)。在未来,随着技术的不断发展和完善,我们有理由相信,GPT-3及其相关技术将为人类社会带来更多的便利和价值。零样本学习:GPT-3具有很好的零样本学习能力,即在没有经过特定任务训练的情况下,也能够完成一些复杂的NLP任务。大规模:GPT-3的参数量达到了1750亿个,是目前已知的最大规模的NLP预训练模型之一。
深度融合大语言模型与知识图谱:思通数科企业知识库智能问答系统的创新实践 2024-05-20 语言模型, 人工智能, 自然语言处理, 知识图谱 286人 已看 本文深入探讨了思通数科如何利用大语言模型和知识图谱技术,构建企业知识库智能问答系统,以促进知识的高效获取、共享、应用和创新,从而提升企业的知识管理水平和业务价值。随着人工智能技术的快速发展,尤其是大语言模型和知识图谱技术的兴起,企业知识管理正迎来新的变革机遇。此外,系统还能够根据业务需求,提供个性化的知识推荐和决策支持,创造更大的业务价值。知识图谱能够将非结构化数据转换为结构化知识,便于检索和分析。深度学习与知识图谱的结合:利用大语言模型的语义理解能力,结合知识图谱的结构化优势,提供精准的知识检索和推荐。