【论文阅读|cryoET】ICE-TIDE 2024-05-23 论文阅读 86人 已看 三维cryoET重建的保真度进一步受到采集过程中物理扰动的影响。这些扰动以各种形式表现出来,例如连续采集之间的样本漂移,导致连续投影未对准,或者由于未散射的电子而导致二维投影中的局部变形。传统的冷冻电子断层扫描工作流程需要对齐倾斜序列图像,然后应用标准重建算法,例如迭代最小二乘法(ILS)、代数重建技术(ART)、同步迭代重建技术(SIRT)或更常见的滤波反投影(FBP)。冷冻电子断层扫描流程的第一步是收集三维样本在不同倾斜角度的投影图像。玻璃化样品只能承受有限剂量的电子而不会受到严重损坏。
【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection 2024-05-24 论文阅读, yolo, 计算机视觉, 目标检测, 人工智能 186人 已看 在过去几年中,YOLOs 因其在计算成本和检测性能之间的有效平衡而成为实时物体检测领域的主流模式。研究人员对 YOLOs 的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,后处理对非最大抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLOs 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余,限制了模型的能力。这使得效率不尽如人意,性能还有很大的提升空间。在这项工作中,我们旨在从后处理和模型架构两方面进一步推进 YOLO 的性能-效率边界。
TENT: FULLY TEST-TIME ADAPTATION BY ENTROPY MINIMIZATION--论文笔记 2024-05-21 论文阅读 415人 已看 在这种完全测试时适应的情况下,模型只有测试数据和自身参数。我们建议通过测试熵最小化(tent)进行适应:我们通过预测熵来优化模型的置信度。我们的方法会估算归一化统计量,并优化通道仿射变换,以便在每个批次上进行在线更新。Tent 降低了损坏的 ImageNet 和 CIFAR-10/100 图像分类的泛化误差,并达到了最先进的误差。在从 SVHN 到 MNIST/MNIST-M/USPS 的数字识别、从 GTA 到 Cityscapes 的语义分割以及 VisDA-C 基准上,Tent 处理了无源域适应。
【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection 2024-05-24 论文阅读, yolo, 计算机视觉, 目标检测, 人工智能 102人 已看 在过去几年中,YOLOs 因其在计算成本和检测性能之间的有效平衡而成为实时物体检测领域的主流模式。研究人员对 YOLOs 的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,后处理对非最大抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLOs 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余,限制了模型的能力。这使得效率不尽如人意,性能还有很大的提升空间。在这项工作中,我们旨在从后处理和模型架构两方面进一步推进 YOLO 的性能-效率边界。
TENT: FULLY TEST-TIME ADAPTATION BY ENTROPY MINIMIZATION--论文笔记 2024-05-21 论文阅读 77人 已看 在这种完全测试时适应的情况下,模型只有测试数据和自身参数。我们建议通过测试熵最小化(tent)进行适应:我们通过预测熵来优化模型的置信度。我们的方法会估算归一化统计量,并优化通道仿射变换,以便在每个批次上进行在线更新。Tent 降低了损坏的 ImageNet 和 CIFAR-10/100 图像分类的泛化误差,并达到了最先进的误差。在从 SVHN 到 MNIST/MNIST-M/USPS 的数字识别、从 GTA 到 Cityscapes 的语义分割以及 VisDA-C 基准上,Tent 处理了无源域适应。
论文笔记《基于深度学习模型的药物-靶标结合亲和力预测》 2024-05-28 论文阅读 69人 已看 例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
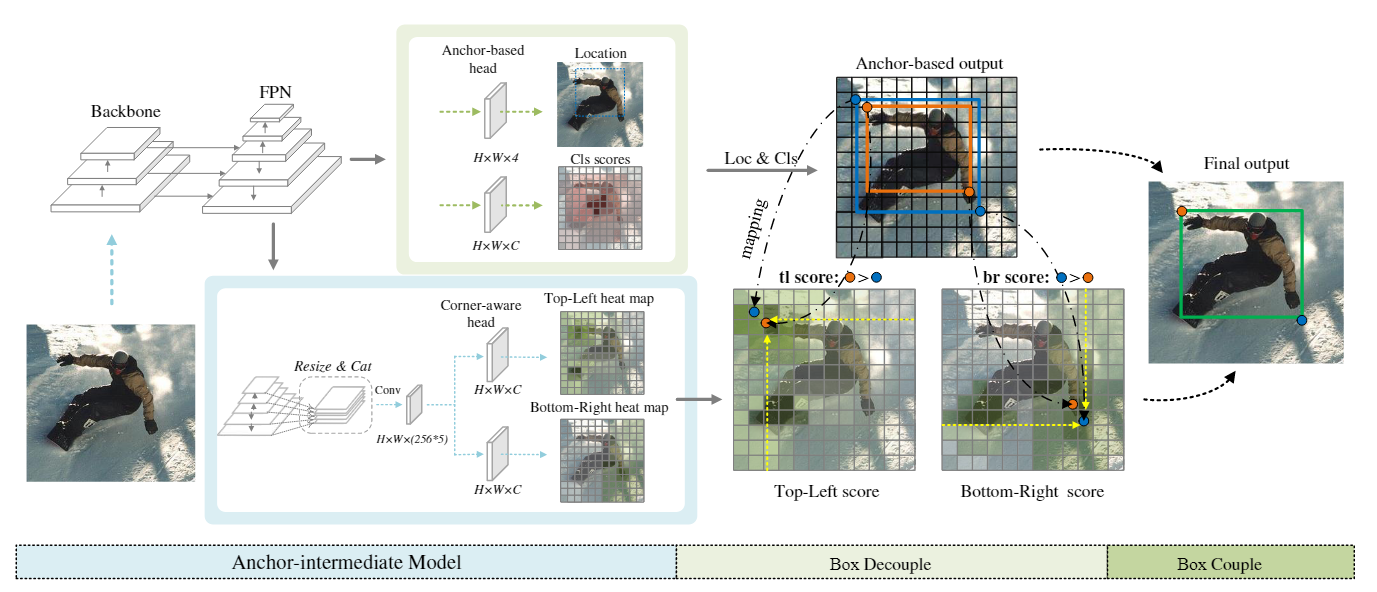
【论文阅读】AID(ICCV‘23) 2024-05-22 论文阅读 73人 已看 Anchor-Intermediate Detector: Decoupling and Coupling Bounding Boxes for Accurate Object Detection(ICCV'23)
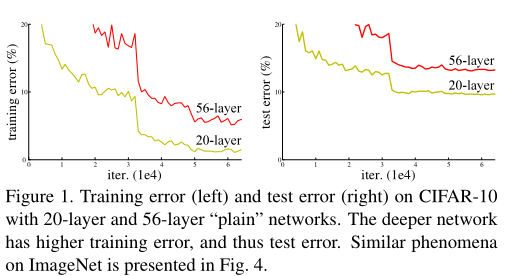
Deep Residual Learning for Image Recognition--论文笔记 2024-05-21 论文阅读 76人 已看 深度神经网络更难训练。我们提出了一个残差学习框架,以简化比以前使用的网络深度大得多的网络的训练。我们明确地将层重新表述为参考层输入的学习残差函数,而不是学习未参考的函数。我们提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从相当大的深度中获得精度。在ImageNet数据集上,我们评估了深度高达152层的残差网络——比VGG网络深度8倍[41],但仍然具有较低的复杂性。这些残差网络的集合在ImageNet测试集上的误差达到3.57%。该结果在ILSVRC 2015分类任务中获得第一名。
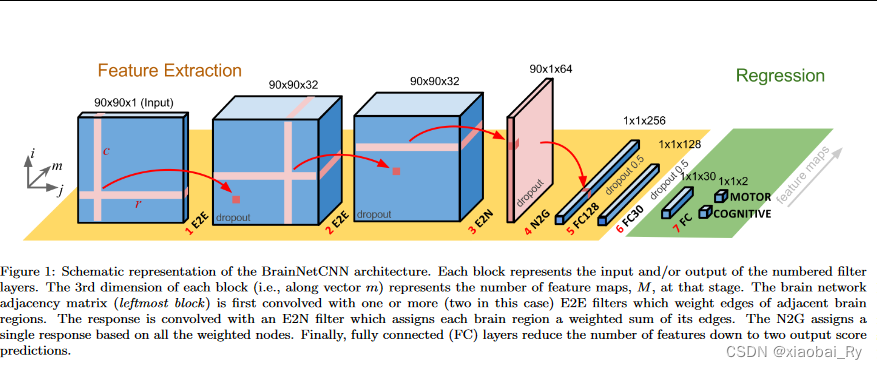
【区域脑图论文笔记】BrainNetCNN:第一个专门为脑网络连接体数据设计的深度学习框架 2024-05-23 论文阅读 79人 已看 核心与其理解核心:BrainNetCNN的核心在于它是第一个专门为脑网络连接体数据设计的深度学习框架(16/17年)。与传统的深度学习框架相比(BrainNetCNN是跟基于图像的CNN框架对比),BrainNetCNN的E2E,E2N,N2G层的设计更有利于脑拓扑局部结构的学习,更具可解释性。核心思想的理解:本质上就是把连接矩阵的每个元素当成节点间边的连接,也就是加权的全连接图。因此,BrainNetCNN其实考虑了连接矩阵的含义。也就是矩阵的每个元素相当于边。
【论文阅读】要使用工具!《Toolformer: Language Models Can Teach Themselves to Use Tools》 2024-05-22 论文阅读, 语言模型, 人工智能, 自然语言处理 139人 已看 语言模型(LMs)表现出了从极少量的示例或文本指令中解决新任务的显著能力,尤其是在模型规模较大时表现的更加显著。矛盾的是,它们也在与基本功能作斗争,如算术或事实查找,在这些功能中,更简单、更小的模型脱颖而出。在本文中,我们展示了LMs可以通过简单的API自学使用外部工具,从而实现两全其美。我们介绍了Toolformer,这是一个经过训练的模型,用于决定调用哪些API,何时调用它们,传递什么参数,以及如何将结果最好地结合到未来的Token预测中。这是以一种自监督的方式完成的,只需要为每个API进行少量的演示。
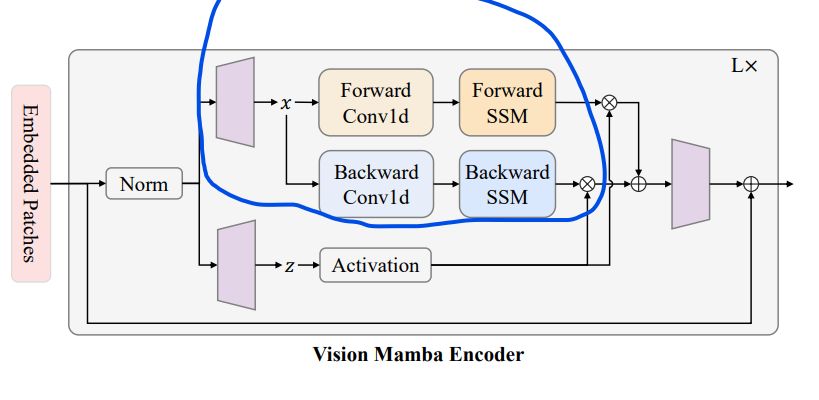
Vision Mamba论文阅读(主干网络) 2024-05-18 论文阅读, 网络 167人 已看 简单看看,文章介绍了Vim模型,这是一种新的通用视觉基础模型,它利用双向Mamba块(bidirectional Mamba blocks (Vim))和位置嵌入 (position embeddings)来处理图像序列,并在ImageNet分类、COCO对象检测和ADE20K语义分割任务上取得了比现有的视觉Transformer模型(如DeiT)更好的性能。指出了Mamba时间复杂度与序列长度是线性的。而Transformer的时间复杂度是与序列长度乘二次方关系。
Deep Residual Learning for Image Recognition--论文笔记 2024-05-21 论文阅读 62人 已看 深度神经网络更难训练。我们提出了一个残差学习框架,以简化比以前使用的网络深度大得多的网络的训练。我们明确地将层重新表述为参考层输入的学习残差函数,而不是学习未参考的函数。我们提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从相当大的深度中获得精度。在ImageNet数据集上,我们评估了深度高达152层的残差网络——比VGG网络深度8倍[41],但仍然具有较低的复杂性。这些残差网络的集合在ImageNet测试集上的误差达到3.57%。该结果在ILSVRC 2015分类任务中获得第一名。
[论文笔记]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 2024-05-21 论文阅读, 语言模型, 人工智能, 自然语言处理, prompt 171人 已看 ⭐ 思维链轮笔记:作者提出了通过生成一系列中间推理步骤的思维链,可以显著提升大型语言模型在进行复杂推理时的能力,但是仅限于100B以上的大模型。
[论文笔记]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 2024-05-21 论文阅读, 语言模型, 人工智能, 自然语言处理, prompt 149人 已看 ⭐ 思维链轮笔记:作者提出了通过生成一系列中间推理步骤的思维链,可以显著提升大型语言模型在进行复杂推理时的能力,但是仅限于100B以上的大模型。
Deep Residual Learning for Image Recognition--论文笔记 2024-05-21 论文阅读 61人 已看 深度神经网络更难训练。我们提出了一个残差学习框架,以简化比以前使用的网络深度大得多的网络的训练。我们明确地将层重新表述为参考层输入的学习残差函数,而不是学习未参考的函数。我们提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从相当大的深度中获得精度。在ImageNet数据集上,我们评估了深度高达152层的残差网络——比VGG网络深度8倍[41],但仍然具有较低的复杂性。这些残差网络的集合在ImageNet测试集上的误差达到3.57%。该结果在ILSVRC 2015分类任务中获得第一名。
Deep Residual Learning for Image Recognition--论文笔记 2024-05-21 论文阅读 76人 已看 深度神经网络更难训练。我们提出了一个残差学习框架,以简化比以前使用的网络深度大得多的网络的训练。我们明确地将层重新表述为参考层输入的学习残差函数,而不是学习未参考的函数。我们提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从相当大的深度中获得精度。在ImageNet数据集上,我们评估了深度高达152层的残差网络——比VGG网络深度8倍[41],但仍然具有较低的复杂性。这些残差网络的集合在ImageNet测试集上的误差达到3.57%。该结果在ILSVRC 2015分类任务中获得第一名。
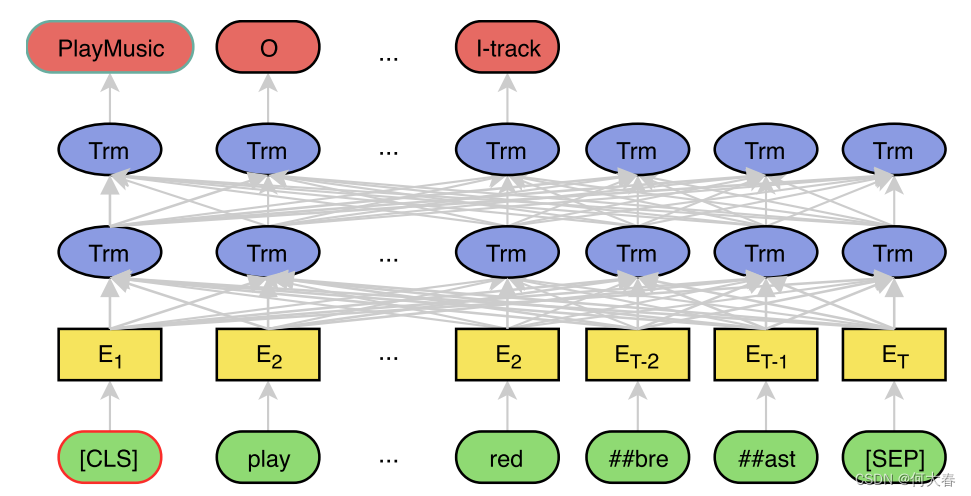
BERT for Joint Intent Classification and Slot Filling 论文阅读 2024-05-15 论文阅读, 深度学习, 人工智能, 自然语言处理, bert 171人 已看 意图分类和槽填充是自然语言理解中两个重要的任务。它们通常受制于规模较小的人工标记训练数据,导致泛化能力较差,特别是对于罕见词汇。最近,一种新的语言表示模型BERT(Bidirectional Encoder Representations from Transformers)在大规模未标记语料库上进行了深度双向表示的预训练,通过简单微调后为各种自然语言处理任务创建了最先进的模型。然而,对于自然语言理解,尚未有太多关于探索BERT的努力。在本工作中,我们提出了一种基于BERT的联合意图分类和槽填充模型。
【论文阅读】要使用工具!《Toolformer: Language Models Can Teach Themselves to Use Tools》 2024-05-22 论文阅读, 语言模型, 人工智能, 自然语言处理 215人 已看 语言模型(LMs)表现出了从极少量的示例或文本指令中解决新任务的显著能力,尤其是在模型规模较大时表现的更加显著。矛盾的是,它们也在与基本功能作斗争,如算术或事实查找,在这些功能中,更简单、更小的模型脱颖而出。在本文中,我们展示了LMs可以通过简单的API自学使用外部工具,从而实现两全其美。我们介绍了Toolformer,这是一个经过训练的模型,用于决定调用哪些API,何时调用它们,传递什么参数,以及如何将结果最好地结合到未来的Token预测中。这是以一种自监督的方式完成的,只需要为每个API进行少量的演示。