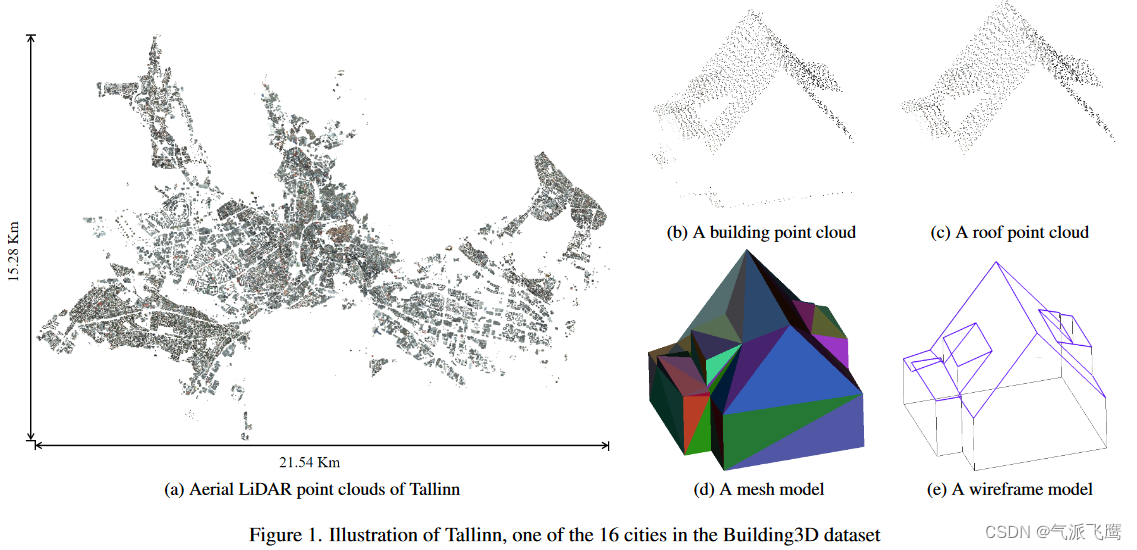
Building3D An Urban-Scale Dataset and Benchmarks 论文阅读 2024-05-14 论文阅读, 3d 98人 已看 提出了一个城市规模的数据集,由超过 16 万座建筑物以及相应的点云、网格和线框模型组成,覆盖爱沙尼亚的 16 个城市,面积约 998 平方公里。通过混淆矩阵计算角点精度(CP)、边缘精度(EP)、角点召回率(CR)和边缘召回率(ER),以评估角点和边缘分类的准确性。本文提出了一种自监督方法和一种无监督方法,与现在常用的点云神经网络提取特征点做基准测试,实验结果见论文原文第4章。数据集包含原始点云,建筑物点云,屋顶点云,以及网格模型和线框模型。ACO 是预测角点和真实角点之间的平均偏移量。
Building3D An Urban-Scale Dataset and Benchmarks 论文阅读 2024-05-14 论文阅读, 3d 79人 已看 提出了一个城市规模的数据集,由超过 16 万座建筑物以及相应的点云、网格和线框模型组成,覆盖爱沙尼亚的 16 个城市,面积约 998 平方公里。通过混淆矩阵计算角点精度(CP)、边缘精度(EP)、角点召回率(CR)和边缘召回率(ER),以评估角点和边缘分类的准确性。本文提出了一种自监督方法和一种无监督方法,与现在常用的点云神经网络提取特征点做基准测试,实验结果见论文原文第4章。数据集包含原始点云,建筑物点云,屋顶点云,以及网格模型和线框模型。ACO 是预测角点和真实角点之间的平均偏移量。
(论文笔记)TABDDPM:使用扩散模型对表格数据进行建模 2024-05-15 论文阅读 56人 已看 去噪扩散概率模型目前正成为许多重要数据模式生成建模的主要范式。扩散模型在计算机视觉社区中最为流行,最近也在其他领域引起了一些关注,包括语音、NLP 和图形数据。在这项工作中,我们研究了扩散模型的框架是否可用于解决表格问题,其中数据点通常由异构特征的向量表示。表格数据固有的异构性使得准确建模变得非常具有挑战性,因为各个特征可能具有完全不同的性质,即其中一些特征可能是连续的,而另一些特征可能是离散的。
【论文阅读】<YOLOP: You Only Look Once for PanopticDriving Perception> 2024-05-09 论文阅读, yolo 75人 已看 全视驾驶感知系统是自动驾驶的重要组成部分。一个高精度的实时感知系统可以帮助车辆在驾驶时做出合理的决策。我们提出了一个全视驾驶感知网络(您只需寻找一次全视驾驶感知网络(YOLOP)),以同时执行交通目标检测、可驾驶区域分割和车道检测。它由一个用于特征提取的编码器和三个用于处理特定任务的解码器组成。我们的模型在具有挑战性的BDD100K数据集上表现得非常好,在准确性和速度方面,在所有三个任务上都实现了最先进的水平。此外,我们通过消融研究验证了我们的多任务学习模型对联合训练的有效性。
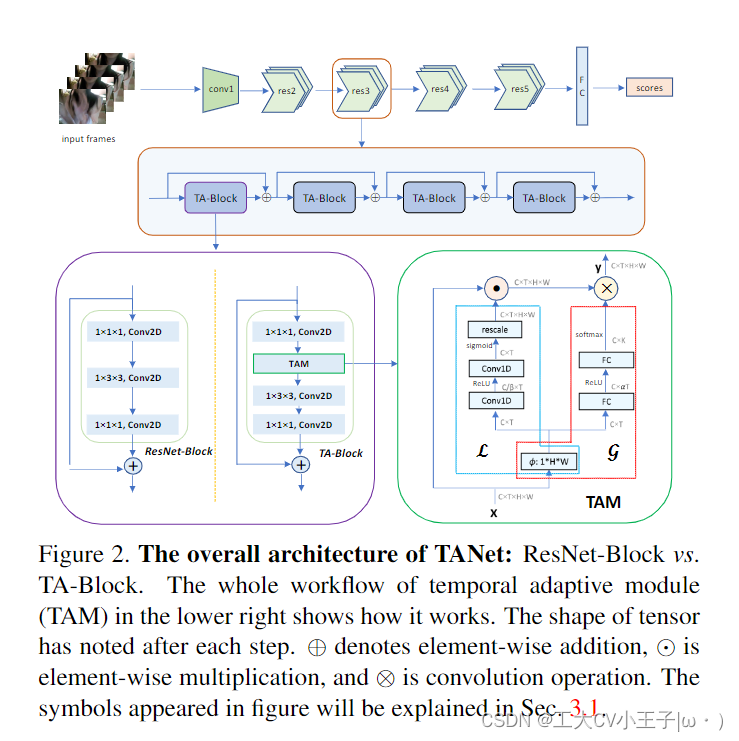
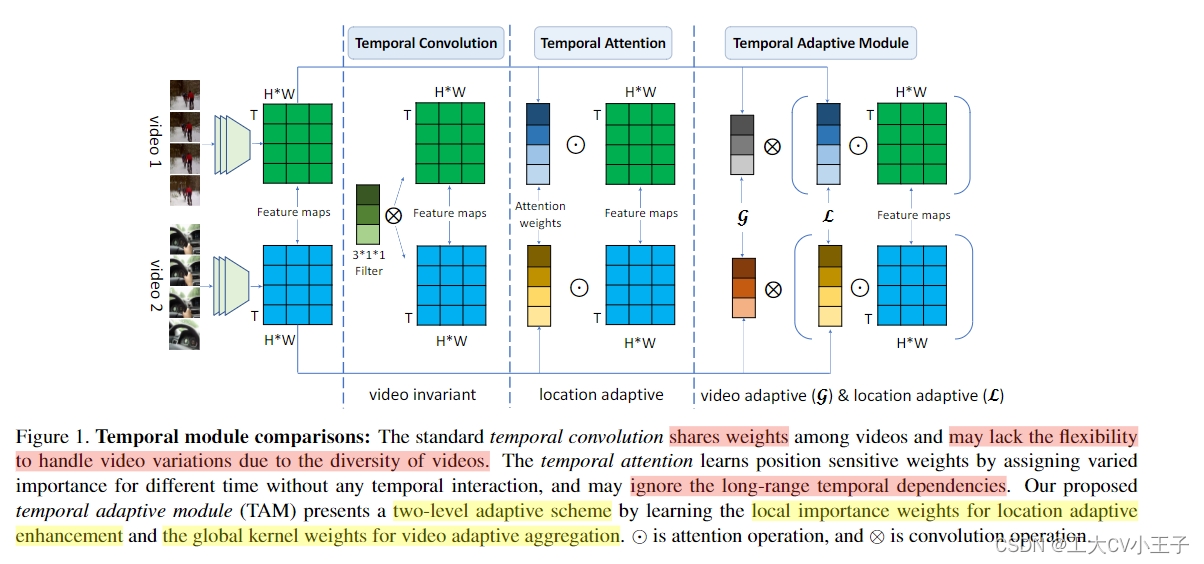
《Tam》论文笔记(下) 2024-05-09 论文阅读 48人 已看 此外,我们的全局分支本质上执行一个视频自适应卷积,其滤波器的大小为1 × k × 1 × 1,而正常3D卷积中的每个滤波器的大小为C × k × k,其中C为通道数,k为接收野。这两个分支侧重于时间信息的不同方面,其中局部分支试图通过使用时间卷积来捕获短期信息以关注重要特征,而全局分支旨在结合远程时间结构来指导具有全连接层的自适应时间聚合。我们的TAM由两个分支组成:局部分支L和一个全局分支G,旨在学习位置敏感的重要性图来增强鉴别特征,然后产生位置不变权值,以卷积的方式自适应地聚合时间信息。
《TAM》论文笔记(上) 2024-05-09 论文阅读 51人 已看 由于相机运动、速度变化和不同活动等因素,视频数据具有复杂的时间动态。为了有效地捕捉这种多样化的运动模式,本文提出了一种新的时间自适应模块(TAM),根据自己的特征图生成视频特定的时间核。TAM提出了一种独特的两级自适应建模方案,将动态核解耦为位置敏感重要性图和位置不变聚合权重。重要性图是在局部时间窗口中学习的,以捕获短期信息,而聚合权重是从全局视图生成的,重点是长期结构。
论文阅读:《Sequence can Secretly Tell You What to Discard》,减少推理阶段的 kv cache 2024-05-07 论文阅读, etl 167人 已看 研究发现在 LLaMA2 系列模型上:(i)相邻 token 的 query 向量之间的相似度非常高,(ii)当前 query 的注意力计算可以完全依赖于一小部分前面 query 的注意力信息。基于这些观察结果,作者提出了一种无需重新训练的 KV 缓存驱逐策略 CORM,通过重复使用最近的 query 注意力信息来显著减少显存占用。通过广泛的评估,作者证明 CORM 可以将 KV Cache 的推理显存使用量减少多达 70%,而在各种任务中不会出现明显的性能下降。
(论文阅读-优化器)Selectivity Estimation using Probabilistic Models 2024-05-06 论文阅读, list 91人 已看 对于涉及多个属性选择和多个关系连接的复杂查询,其结果大小的估计是数据库查询处理中一项困难而又基本的任务。它出现在基于成本的查询优化、查询分析和近似查询回答中。在本文中,我们展示了如何有效地使用概率图形模型作为跨多个关系的多个属性联合频率分布的精确和紧凑的逼近来完成这项任务。概率关系模型(Probabilistic Relational Models, PRMs)是最近的一项发展,它将图形统计模型(如贝叶斯网络)扩展到关系领域。它们表示表中属性之间以及跨外键连接的属性之间的统计依赖关系。
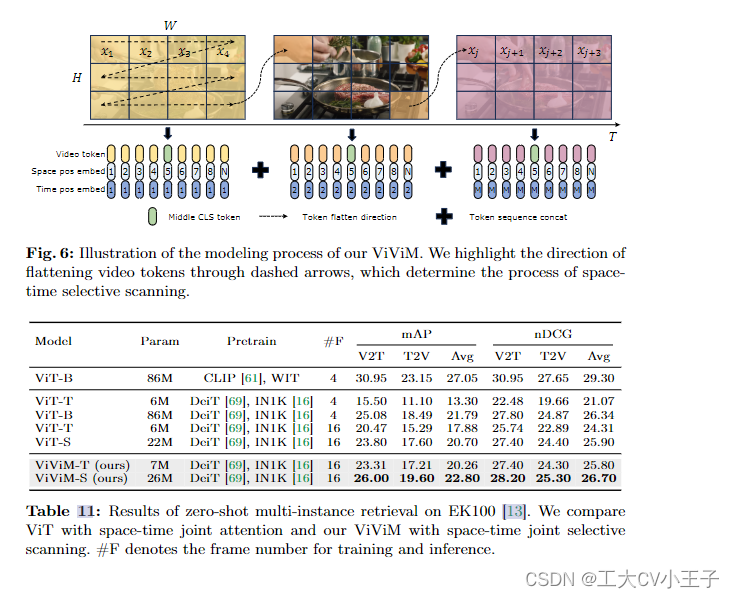
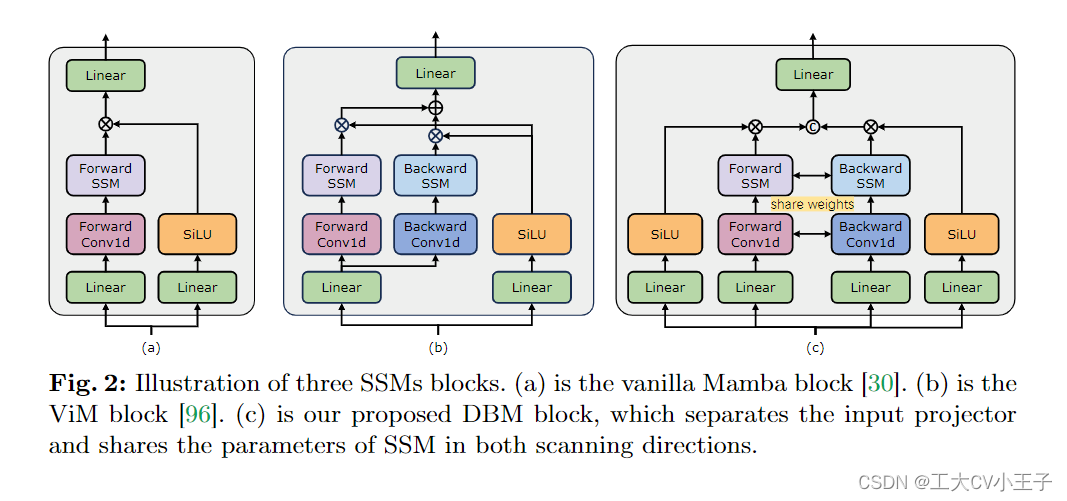
《Video Mamba Suite》论文笔记(4)Mamba在时空建模中的作用 2024-05-06 论文阅读 53人 已看 对于由 M 帧组成的给定输入,我们在对应于每一帧的标记序列的中间插入 cls 标记。有趣的是,尽管 ImageNet-1K 上 ViT-S [69] 和 ViM-S [96] 之间的性能差距很小(79.8 vs. 88.5),ViViM-S 在零样本多实例检索上显示出比 ViT-S 的显着改进(+2.1 mAP@Avg)。通过Video Mamba Suite,包括14个模型/模块12个视频理解任务,我们证明了Mamba能够有效地处理复杂的时空动态,表现出优越的性能和有前途的效率-性能权衡。
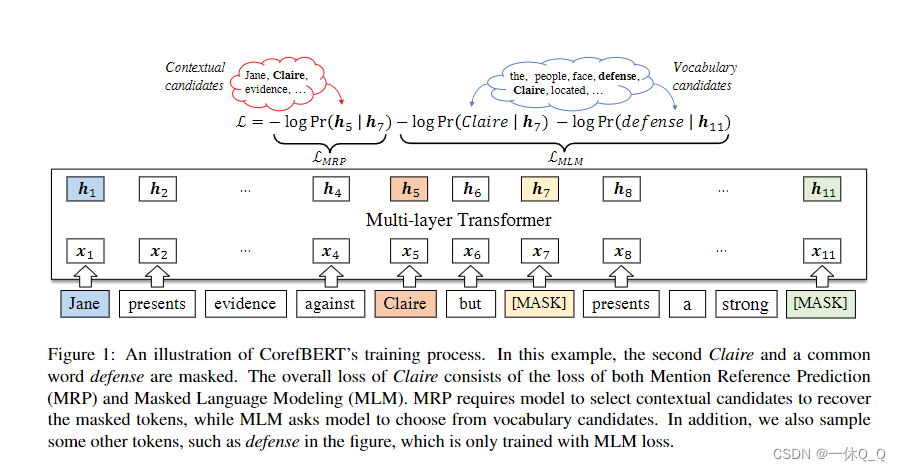
corefBERT论文阅读 2024-05-06 论文阅读 51人 已看 corefBERT语言表示模型,可以更好的捕获和表示共引用信息。corefBERT引入一种新的预训练任务MRP(mention refenrece prediction),MRP利用重复出现的提及获得丰富的共指关系。MRP使用掩码方法遮盖一个或者多个提及,模型预测被遮盖住的整个提及。根据上图,词的损失由MRP提及参考预测和MLM遮盖语言建模损失两部分构成。
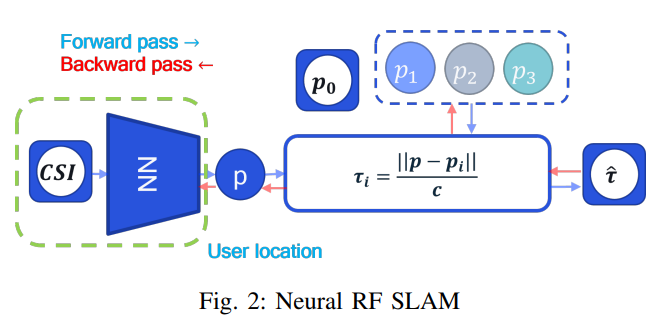
【论文阅读】通信定位技术《Neural RF SLAM for unsupervised positioning and mapping with channel state information》 2024-05-06 论文阅读 54人 已看 文章的思路是通过SLAM技术,在无监督的方式下,通过没有标记位置信息的信道状态信息(CSI)实现联合用户定位和环境构建,此方法不增加额外的现场数据标注成本,并且适应性更好
论文阅读_RAG融合现有知识树_T-RAG 2024-05-05 论文阅读 44人 已看 开发一个可以安全、高效地回答私有企业文档问题的大型语言模型(LLM)应用程序,主要考虑数据安全性、有限的计算资源以及需要健壮的应用程序来正确响应查询。
(论文阅读-分析引擎)Modin 2024-05-07 论文阅读 55人 已看 目标是在不改变的Dataframe语义的情况下支持可扩展的dataframe操作。什么是机会主义评价?Exploratory data analysis(EDA):总结、理解并从数据集中获取价值的过程。MPI:MPI是高性能计算常用的实现方式,它的全名叫做Message Passing Interface。顾名思义,它是一个实现了消息传递接口的库。并行计算之MPI篇 · XTAO AchelousOpenMP(Open Multi-Processing)是一套支持跨平台共享内存方式的多线程并发的编程。
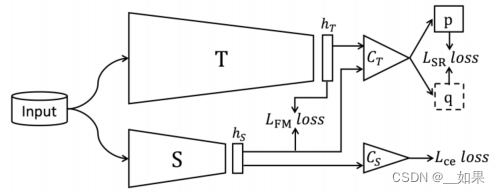
论文阅读--Knowledge distillation via softmax regression representation learning 2024-04-29 论文阅读 61人 已看 这篇论文解决了通过知识蒸馏进行模型压缩的问题。我们主张一种优化学生网络倒数第二层输出特征的方法,因此与表示学习直接相关。为此,我们首先提出了一种直接特征匹配方法,重点优化学生网络的倒数第二层。其次,更重要的是,因为特征匹配没有考虑到手头的分类问题,我们提出了第二种方法,将表示学习和分类解耦,并利用教师的预训练分类器来训练学生的倒数第二层特征。特别是,对于相同的输入图像,我们希望通过教师的分类器传递时,教师和学生的特征产生相同的输出,这通过简单的 L2 损失实现。
《Video Mamba Suite》论文笔记(1)Mamba在时序建模中的作用 2024-05-06 论文阅读 86人 已看 理解视频是计算机视觉研究的基本方向之一,在大量致力于探索 RNN、3D CNN 和 Transformer 等各种架构的工作的努力下。新提出的状态空间模型架构,例如 Mamba,展现出了其能够将长序列建模方面的成功扩展到视频建模领域的良好特性。为了评估 Mamba 是否可以成为视频理解领域中 Transformer 的可行替代方案在这项工作中,我们进行了一组全面的研究,探索 Mamba 在视频建模中可以扮演的不同角色,同时研究 Mamba 可能展现出良好性能的不同任务。