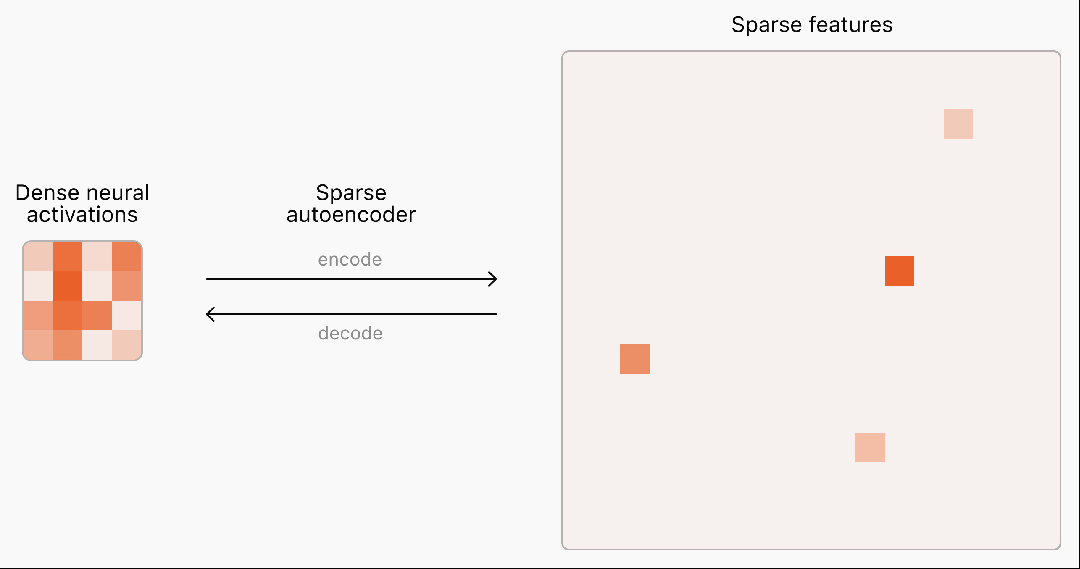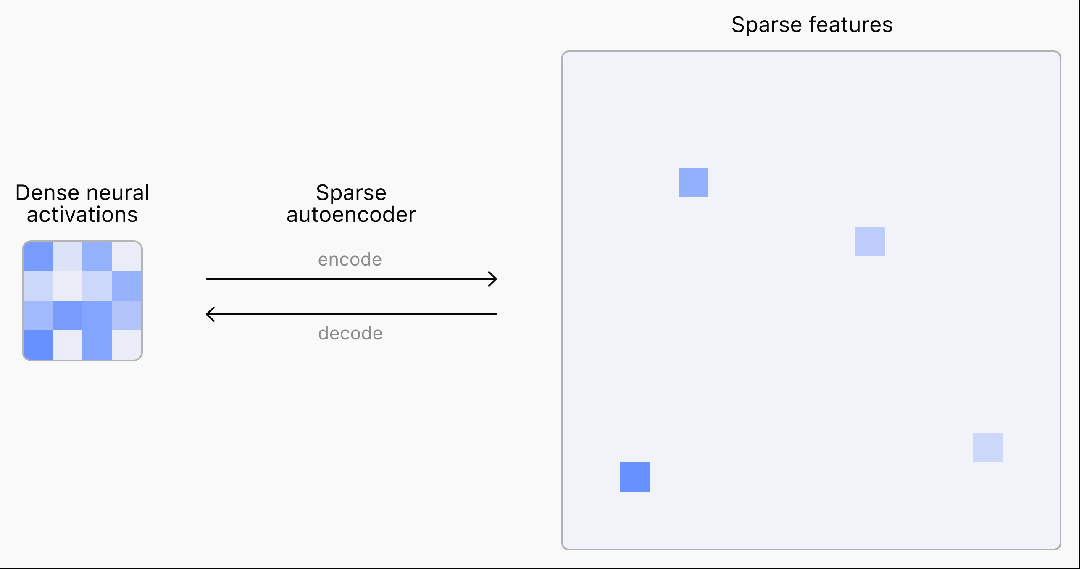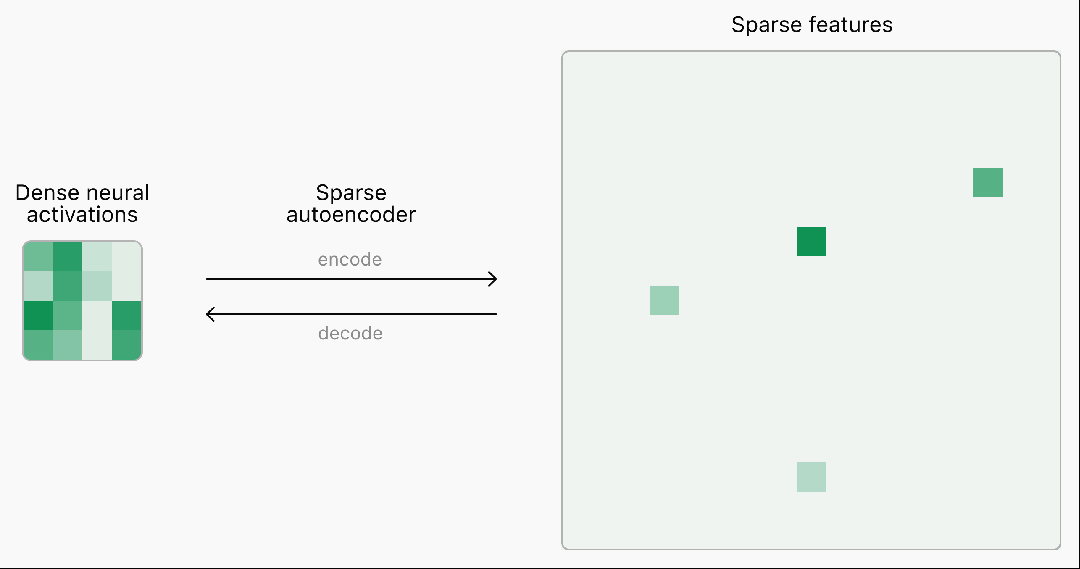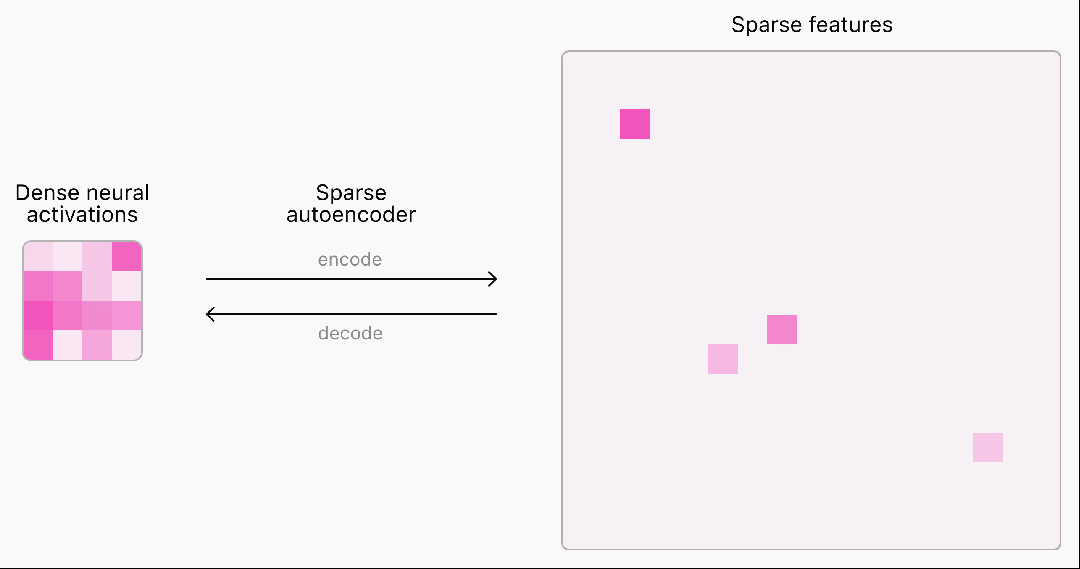
在OpenAI超级对齐团队的这项研究中,他们推出了一种基于TopK激活函数的新稀疏自编码器(SAE)训练技术栈,消除了特征缩小问题,能够直接设定L0(直接控制网络中非零激活的数量)。具体来说,他们使用GPT-2 small和GPT-4系列模型的残差流作为自编码器的输入,选取网络深层(接近输出层)的残差流,如GPT-4的5/6层、GPT-2 small的第8层。团队还提出了多重TopK损失函数的改进方案,提高了高稀疏情况下的泛化能力,并且探讨了两种不同的训练策略对latent数量的影响,这里就不过多展开了。