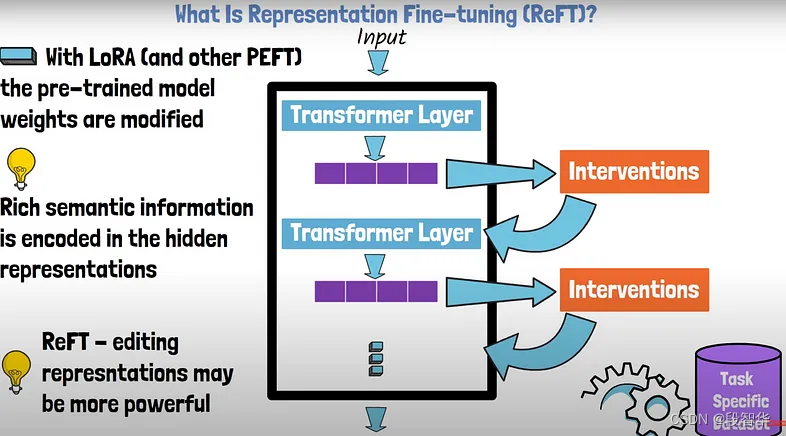
目前具有代表性的混合专家模型是 Mixtral (8×7B),该模型在 Mistral (7B) 的基础上,使用了混合专家模块。在每次计算被激活的参数仅仅有 13B的情况下,其性能超越了规模更大的 LLaMA-2 (70B),进一步证明了混合专家架构的有效性。为了解决这一问题,研究人员在大语言模型中引入了基于稀疏激活的混合专家架构(Mixture-of-Experts, MoE),旨在不显著提升计算成本的同时实现对于模型参数的拓展。之后,每个被选择的词元的输出的加权和将作为该混合专家网络层的最终输出。