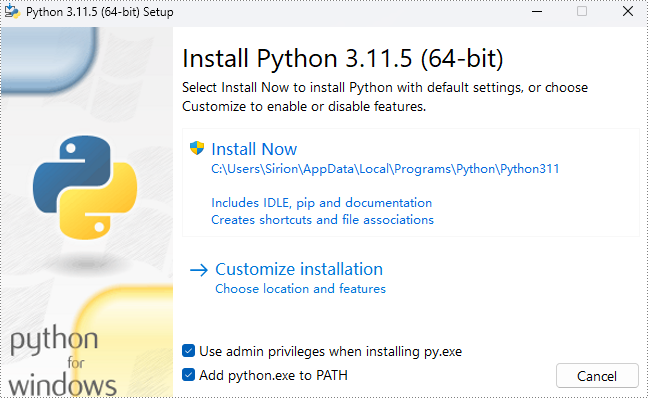
如何在 Windows 中安装 Spire.PDF for Python 2024-06-18 python, pdf, 开发语言 419人 已看 Spire.PDF for Python 是一款完全独立的 PDF 开发组件,用于在任何 Python 应用程序中读取、创建、编辑和转换 PDF 文件。
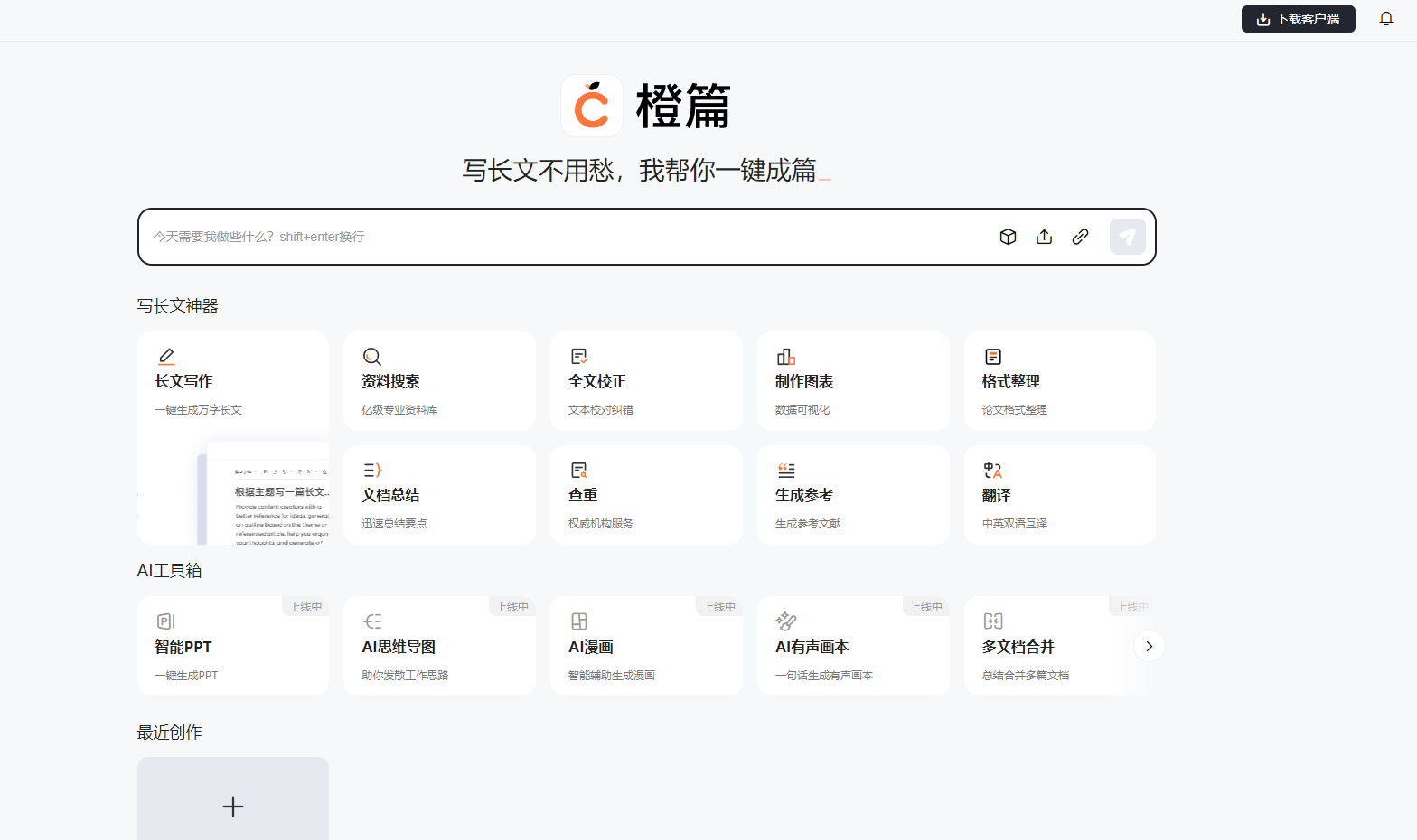
百度文库AI产品“橙篇”:支持10万字长文生成,开启AI创作新篇章 2024-06-21 人工智能 147人 已看 6月19日,百度文库发布了一款创新产品「橙篇」,这一行业首创的产品集成了10万字长文生成及多模态编辑能力,成为首个实现「查阅创编」一站式AI自由创作平台的里程碑。
chatgpt的原理是什么 2024-06-21 chatgpt 239人 已看 ChatGPT 的核心原理是基于 Transformer 架构,通过大量文本数据的预训练和针对特定任务的微调,模型能够生成自然语言文本。ChatGPT 是基于 OpenAI 开发的 GPT(Generative Pre-trained Transformer)系列模型,它的原理依赖于深度学习、自然语言处理(NLP)以及 Transformer 架构。GPT 只使用解码器部分来生成文本。这通常包括人类标注的数据集,使用类似于自然语言生成、问答等任务的训练目标来调整模型的参数,使其能够更好地执行这些任务。
Springboot项目ES报异常query_shard_exception 2024-06-15 spring, java, elasticsearch, servlet, 后端 296人 已看 而参数brandId是List类型,允许传入多个值,因此使用termQuery是错误的,它只能传入一个值,很明显是这里调错方法了,多个值的集合、数组,应该使用termsQuery方法,把方法调整过来就不报错了。从caused_by找出导致异常的根本原因,For input string:\"|""。因为查询参数中传入了数组,再查看项目中构建DSL语句,终于找到异常爆发的原因了,
数据库面试题-ElasticSearch 2024-06-18 elasticsearch, 全文检索, 搜索引擎, 大数据 246人 已看 TF-IDF(Term Frequency - lnverse Document Frequency)是一种用于评估词语在文档集中的重要性的统计方法。它通过计算词频(TF)和逆文档频率(IDF)的乘积来工作。词频指一个词在文档中出现的次数,而逆文档频率是用来衡量一个词是否常见或是稀有的度量,计算方法是文档集中文档总数除以包含该词的文档数的对数。TF-IDF值越高,表示词在文档中越重要。
热词排序算法——贝叶斯均值法 2024-06-18 算法, 机器学习, 人工智能, 均值算法, 排序算法 366人 已看 当前(例如今天)的某个词出现的频率相比于历史发生突增,那么这个词的热度上升,如何修正排名呢?
【大数据】gRPC、Flink、Kafka 分别是什么? 2024-06-18 flink, kafka, 分布式, 大数据 348人 已看 Apache Flink 是一个开源的流处理框架,用于处理无界和有界数据流。它是一个分布式处理引擎,支持实时数据流处理和批处理任务。Flink 被广泛应用于大数据分析、机器学习、实时监控和复杂事件处理等领域。
Python&SQL应用随笔4——PySpark创建SQL临时表 2024-06-15 python, spark, 大数据, 开发语言, sql 412人 已看 本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。
简单介绍vim 2024-06-18 编辑器, linux, vim 312人 已看 Vim是一款强大的文本编辑器,被广泛用于各种编程和文本编辑任务。它起源于Vi,一个古老的Unix文本编辑器,但Vim(Vi Improved)提供了更多的功能和改进。Vim具有模式化的编辑界面,主要包括普通模式、插入模式、命令模式等,每种模式都有各自的操作方式和快捷键,这种设计使得Vim在编辑文本时非常高效。Vim的学习曲线相对较陡峭,因为它的操作方式和快捷键与大多数常见的文本编辑器不同。但是,一旦掌握了Vim的基本操作,你会发现Vim的编辑效率远远超过其他编辑器。
【LeetCode:2663. 字典序最小的美丽字符串 + 贪心】 2024-06-22 算法, python, leetcode, 职场和发展, 开发语言 213人 已看 【LeetCode:2663. 字典序最小的美丽字符串 + 贪心】如果一个字符串满足以下条件,则称其为 美丽字符串 :- 它由英语小写字母表的前 k 个字母组成。- 它不包含任何长度为 2 或更长的回文子字符串。给你一个长度为 n 的美丽字符串 s 和一个正整数 k 。请你找出并返回一个长度为 n 的美丽字符串,该字符串还满足:在字典序大于 s 的所有美丽字符串中字典序最小。如果不存在这样的字符串,则返回一个空字符串。对于长度相同的两个字符串 a 和 b ,如果字符串 a 在与字符串 b 不
Redis源码学习:跳表(Skip List)的工作原理详解 2024-06-21 学习, list, windows, 数据结构 396人 已看 跳表(Skip List),首先它是链表,是一种随机化的数据结构,Redis 使用跳表作为有序集合(Sorted Set)的底层实现之一。跳表能够提供高效的插入、删除、查找操作。本文通过阅读源码来分析跳表的工作原理。Redis 的跳表通过多级索引结构,实现了高效的插入、删除和查找操作。希望这篇文章能够帮助你更好地理解跳表的工作原理和实现细节。
热词排序算法——贝叶斯均值法 2024-06-18 算法, 机器学习, 人工智能, 均值算法, 排序算法 342人 已看 当前(例如今天)的某个词出现的频率相比于历史发生突增,那么这个词的热度上升,如何修正排名呢?
一篇文章了解常用排序算法 2024-06-18 算法, java, 排序算法, 数据结构, 开发语言 263人 已看 排序文章目录排序直接(插入)排序InsertSort思想实现方法:希尔排序ShellSort(可过OJ)思想预排序gap的作用整体代码选择排序SelectSort思想完整代码堆排序HeapSort(可过OJ)思想大根堆向下调整完整代码冒泡排序BubbleSort快速排序(快排)QuickSort缺陷三数取中法,规避缺陷情况快排的实现方式双(左右)指针法挖坑法前后指针法快排的非递归方式归并排序(外排序)MergeSort (像后序遍历)(可过OJ)归并排序的内存中(内排序)实现方法归并排序内排序的非递归归并
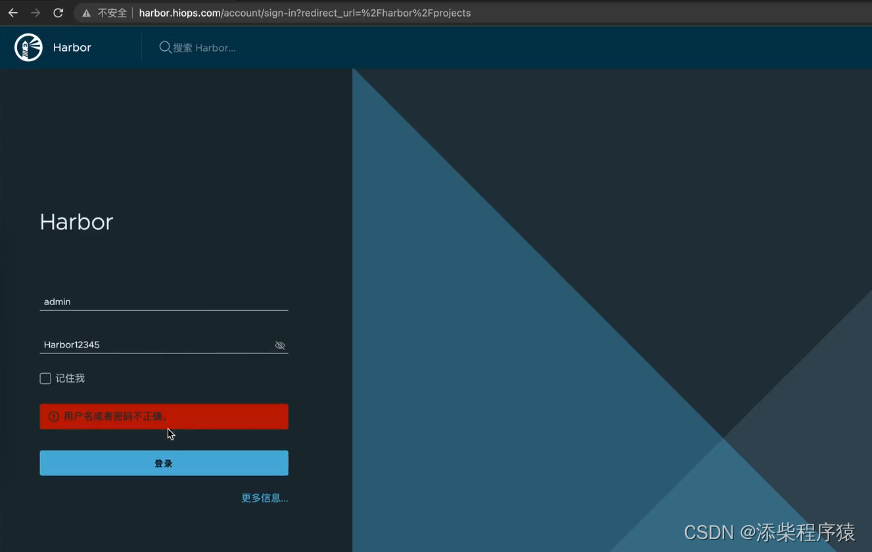
Harbor本地仓库搭建003_Harbor常见错误解决_以及各功能使用介绍_镜像推送和拉取---分布式云原生部署架构搭建003 2024-06-18 云原生, 架构, 分布式 259人 已看 然后点开这个镜像,可以看到对应的artifacts还有,他的tags,我们设站点1.15.12对吧。可以看到添加上,忽略的域名就可以了,让docker,对我们的地址,忽略https检测。首先我们去登录一下harbor,但是可以看到,用户名密码没有错,但是登录不上去。是因为,我们用了负债均衡,nginx会把,负载均衡进行,随机分配,访问的。的business这个项目,可以看到在镜像仓库中,就有了。登录以后,可以看到项目中,我们可以创建一个项目,比如。可以看到我们给,负载均衡,分发的时候,添加上。
redis类型解析汇总 2024-06-21 哈希算法, 缓存, 数据库, windows, redis 629人 已看 Redis(Remote Dictionary Server 远程字典服务器)是一个开源的内存数据库,它可以作为缓存、数据库和消息中间件使用Redis 最基本的数据类型,可以存储文本、整数或者二进制数据。支持基本的字符串操作,如设置、获取、追加等。类似于关联数组,适合存储对象。每个哈希可以存储多个字段和对应的值。链表结构,支持从两端压入和弹出元素,适合存储有序的元素集合。可以用于实现队列、栈等数据结构。无序且唯一的元素集合,支持集合间的基本操作(交集、并集等)。