【大数据】gRPC、Flink、Kafka 分别是什么? 2024-06-18 flink, kafka, 分布式, 大数据 294人 已看 Apache Flink 是一个开源的流处理框架,用于处理无界和有界数据流。它是一个分布式处理引擎,支持实时数据流处理和批处理任务。Flink 被广泛应用于大数据分析、机器学习、实时监控和复杂事件处理等领域。
Python&SQL应用随笔4——PySpark创建SQL临时表 2024-06-15 python, spark, 大数据, 开发语言, sql 334人 已看 本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。
大数据学习-Hadoop 2024-06-21 hadoop, 分布式, 大数据 289人 已看 分布式大数据存储——HDFS 组件分布式大数据计算——MapReduce 组件分布式资源调度——YARN 组件可以通过它来构建集群,完成大数据的存储和计算学习起来相对简单,市场占有率高,为后续的其他大数据软件学习打下基础这里学习的是 Hadoop 开源版它是 Hadoop 的一个组件,用来进行分布式计算的一个框架;计算的模式:分散-汇总模式提供了两个接口Map,提供“分散”功能,由多个服务器分布式地对数据进行处理Reduce,提供“汇总”功能,将分布式计算的结果进行汇总。
数据治理在数据提取中的角色:确保数据质量和安全 2024-06-20 安全, 大数据 149人 已看 数据治理在数据提取过程中扮演着至关重要的角色,它不仅能够确保数据的准确性和安全性,还能够促进数据的共享和协同。在数字化时代,企业应充分认识到数据治理的重要性,并积极探索和实践数据治理的最佳路径,以构建更加完善的数据治理体系,为企业的发展提供坚实的数据支持。
名校介绍|英国六所红砖大学 2024-06-21 人工智能, 大数据 173人 已看 近年来由于美国的拒签率增加,很多公派申请者,尤其是CSC资助的访问学者、公派联合培养学生及博士后研究学者,把出国目标改为其它发达国家,尤以英国居多,本文知识人网小编就重点介绍六所英国红砖大学。
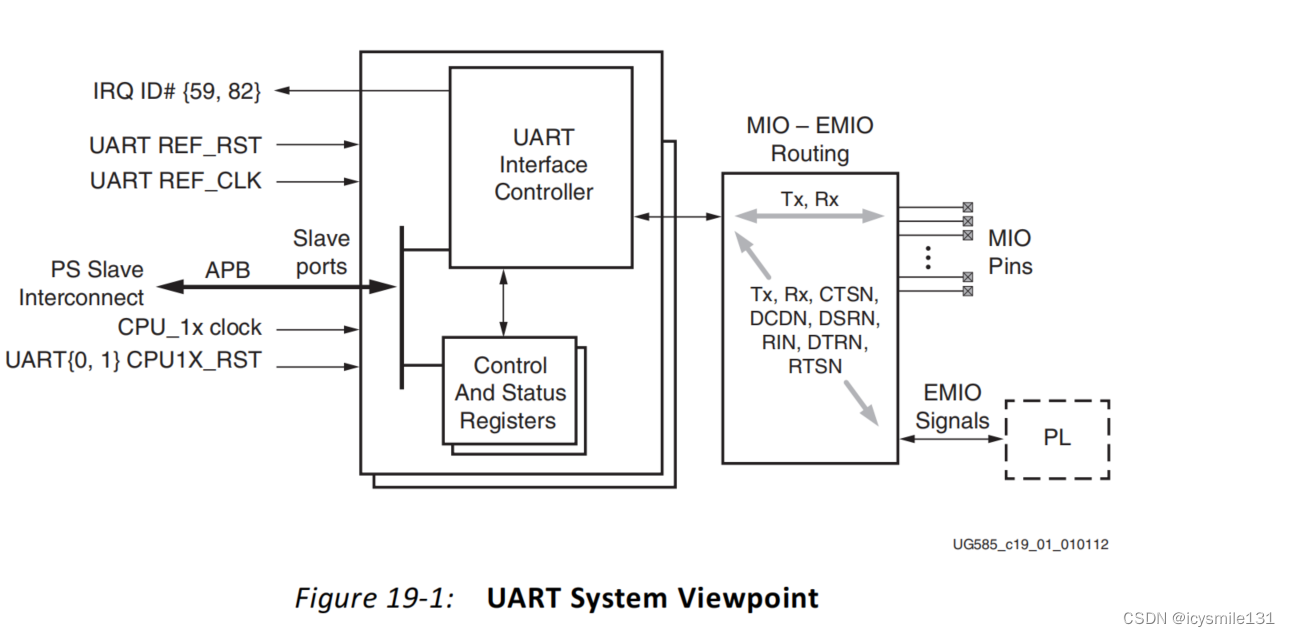
ZYNQ7 Processing System IP核中PS侧Uart的用法 2024-06-14 elasticsearch, 全文检索, 搜索引擎, 大数据, 单片机 267人 已看 ZYNQ7 Processing System IP核中PS侧Uart的用法
MapReduce中shuffle阶段的工作流程,如何优化shuffle阶段? 2024-06-17 mapreduce, 大数据 207人 已看 在MapReduce框架中,shuffle阶段是一个关键步骤,负责将Mapper输出的数据分配给适当的Reducer。
武汉工程大学24计算机考研数据,有学硕招收调剂,而专硕不招收调剂! 2024-06-20 大数据 135人 已看 武汉工程大学是一所以工为主,覆盖工、理、管、经、文、法、艺术、医学、教育学等九大学科门类的多科性教学研究型大学,是湖北省重点建设高校、湖北省国内一流学科建设高校,入选卓越工程师教育培养计划、中西部高校基础能力建设工程、“新工科”研究与实践项目。1.光电复试成绩计算:复试成绩=专业课笔试*40%+(英语能力测试+综合面试)*60%。计算机复试成绩=专业素养成绩*37.5%+(外国语成绩+综合素质成绩)*62.5%。初试总分500分专业:总成绩=(初试成绩/5)*60%+复试成绩*40%。
【HiveSQL】join关联on和where的区别及效率对比 2024-06-17 hive, 数据仓库, hadoop, 大数据, sql 278人 已看 假设数据库系统支持谓词下推的前提下,内连接:内连接的两个执行计划中,对t2表都使用了,对t1表都使用了,因此可以说,内连接中where和on在执行效率上没区别。外连接:还是拿左外连接来说,右表相关的条件会使用谓词下推,而左表是否会提前过滤数据,取决于where还是on以及筛选条件是否与左表相关,1)当为on时,左表的数据必须全量读取,此时效率的差别主要取决于左表的数据量。2)当为where时,如果筛选条件涉及到左表,则会进行数据的提前过滤,否则左表仍然全量读取。
从零手写实现 nginx-21-modules 模块 2024-06-13 nginx, elasticsearch, 运维, 搜索引擎, 大数据 221人 已看 大家好,我是老马。很高兴遇到你。我们为 java 开发者实现了 java 版本的 nginx如果你想知道 servlet 如何处理的,可以参考我的另一个项目:手写从零实现简易版 tomcatminicat大家好,我是老马。这一节我们来系统的看一下 nginx 有哪些模块,为我们后续的设计实现打下基础。
Flink DataSink介绍 2024-06-19 flink, c#, linq, 大数据 239人 已看 Flink DataSink是Apache Flink框架中负责将数据流发送到外部系统或存储介质的关键组件。以下是两个简单的代码示例,一个展示了如何自定义一个简单的。在使用Kafka连接器之前,请确保已经添加了Flink的Kafka连接器的依赖到你的项目中。请注意,你需要根据你的Flink版本和Kafka版本调整依赖和配置。,另一个展示了如何使用Flink的Kafka连接器将数据写入Kafka。在上面的Kafka连接器示例中,我们使用了。应该替换为你的Kafka集群的实际地址。
Flink 容错 2024-06-15 flink, 大数据 191人 已看 Apache Flink 的容错机制通过创建检查点、提供状态一致性保证、支持多种状态存储后端以及提供灵活的容错配置参数和重启策略,确保了在分布式环境中执行数据流应用程序时的高可用性和容错性。这使得 Flink 成为一个强大而可靠的数据处理框架。
数据资产管理的未来趋势:洞察技术前沿,探讨数据资产管理在云计算、大数据、区块链等新技术下的发展趋势 2024-06-15 区块链, 大数据, 云计算 278人 已看 企业需要紧跟技术前沿,积极探索和实践新技术在数据资产管理中的应用,以实现数据资产的最大化利用和价值创造。“方案365”全新整理数据资产、乡村振兴规划设计、智慧文旅、智慧园区、数字乡村-智慧农业、智慧城市、数据治理、智慧应急、数字孪生、乡村振兴、智慧乡村、元宇宙、数据中台、智慧矿山、城市生命线、智慧水利、智慧校园、智慧工地、智慧农业、智慧旅游等300+行业全套解决方案。大数据技术可以处理和分析各种类型的数据,包括结构化数据、非结构化数据等,为企业提供更加全面和准确的数据支持。
大数据之flink与hive 2024-06-10 hive, flink, 数据仓库, hadoop, 大数据 291人 已看 其实吧我不太想写flink,因为线上经验确实不多,这也是我需要补的地方,没有条件创造条件,先来一篇吧。