YOLOv9改进策略 | 添加注意力篇 | 利用YOLO-Face提出的SEAM注意力机制优化物体遮挡检测(附代码 + 修改教程) 2024-05-09 yolo, 计算机视觉, 深度学习, 人工智能 177人 已看 本文给大家带来的改进机制是由YOLO-Face提出能够改善物体遮挡检测的注意力机制SEAM,注意力网络模块旨在补偿被遮挡面部的响应损失,通过增强未遮挡面部的响应来实现这一目标,其希望通过学习遮挡面和未遮挡面之间的关系来改善遮挡情况下的损失从而达到改善物体遮挡检测的效果,本文将通过介绍其主要原理后,提供该机制的代码和修改教程,并附上运行的yaml文件和运行代码,小白也可轻松上手。。欢迎大家订阅我的专栏一起学习YOLO!YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏目录。
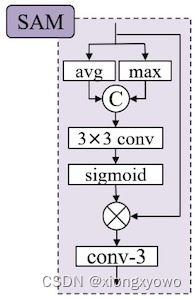
每日Attention学习4——Spatial Attention Module 2024-05-09 学习, python, 深度学习, pytorch, 人工智能 437人 已看 我们设计了空间注意力模块 (SAM),以有效地完善特征(见图 3)。我们首先沿通道轴使用平均和最大运算,分别生成两个不同的单通道空间图$S_{avg}$和$S_{max}$。然后,我们将它们连接起来,通过3×3卷积和sigmoid函数计算出空间注意力图。空间注意力图$M_{sa}$可以通过元素级相乘从空间维度对特征重新加权。最后,细化后的特征被送入3×3卷积层,将通道压缩至64。
【深度学习】--slowfast视频理解数据集处理pipeline 2024-05-10 音视频, 深度学习 100人 已看 缺点,这两个都没有 排除帧,所谓排除帧, 就是所有帧里面都是有目标的。这样的话,就会造成后面的配置文件有个别文件不起作用。谁知道哪两个文件有排除帧,欢迎评论区见。主要是采样目标后还要还原,还原的不对当下不知道,得训练的时候才知道,而且没法和原来的数据做对比。将配置文件需要的文件都裁切成只包含后面这两个文件,这里面坑很多,我是试出来的,所以记录一下。我要是现在linux上打开就好了,光挨个窜这几个文件窜了2天哎!我的这个文件,能够一键生成目标数据集的配套内容。打开视频汇总的文件,挑两个下载。
深度学习之DCGAN 2024-05-06 深度学习, 人工智能 93人 已看 DCGAN,全称是 Deep Convolution Generative Adversarial Networks(深度卷积生成对抗网络),是 Alec Radfor 等人于2015年提出的一种模型。该模型在 Original GAN 的理论基础上,开创性地 将 CNN 和 GAN 相结合 以 实现对图像的处理,并提出了一系列对网络结构的限制以提高网络的稳定性。DCGAN和GAN明显的区别就是,他的生成器使用的是转置卷积层,判别器使用的是卷积层。
【深度学习】【Lora训练0】StabelDiffusion,Lora训练,kohya_ss训练 2024-05-09 深度学习, 人工智能 100人 已看 资源:(1)训练ui kohya_ss:(2)kohya_ss 的docker+ 其他docker。
【基于 PyTorch 的 Python 深度学习】5 机器学习基础(3) 2024-05-09 python, 机器学习, 深度学习, pytorch, 人工智能 100人 已看 根据吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》撰写的学习笔记,该篇主要介绍了单 GPU 加速和多 GPU 加速,以及使用 GPU 的注意事项。
pytorch中的数据集处理部分data_transforms = { ‘train‘: transforms.Compose([...])... 2024-05-06 python, 机器学习, 深度学习, pytorch, 人工智能 115人 已看 在PyTorch的深度学习框架中,是一个非常常用的工具,它用于将多个数据转换(或称为“变换”)组合成一个单一的转换流程。这通常用于预处理输入数据,比如图像,以符合模型的训练要求。当你看到这样的代码时,这通常是在一个字典中定义数据预处理流程,其中'train'是键,表示这是用于训练数据的预处理流程。例如,以下是一个常见的图像预处理流程,它使用了在这个例子中,ToTensor()当你使用这样的预处理流程时,你可以确保你的模型在训练时接收到经过适当预处理的数据。
卷积通用模型的剪枝、蒸馏---蒸馏篇--RKD关系蒸馏(以deeplabv3+为例) 2024-05-09 python, 机器学习, 深度学习, 人工智能, 剪枝 268人 已看 本文以deeplabv3+为例,采用RKD蒸馏方法,实现了剪枝前模型对剪之后模型的蒸馏训练。
英伟达推出视觉语言模型:VILA 2024-05-06 算法, 语言模型, 计算机视觉, 深度学习, 人工智能 107人 已看 1.情境学习与泛化能力:VILA通过预训练不仅提升了情境学习能力,即模型对新情境的适应性和学习能力,而且还优化了其泛化能力,使模型能在不同的视觉语言任务上展现出色的性能。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。3.融合层:融合层是VILA模型的核心,它负责整合来自视觉处理单元和语言处理单元的信息,生成统一的、多模态的表示,这对于执行跨模态任务至关重要4.优化策略:包括技术如弹性权重共享和梯度截断,这些策略帮助模型在训练过程中保持稳定,并优化跨模态信息的流动。
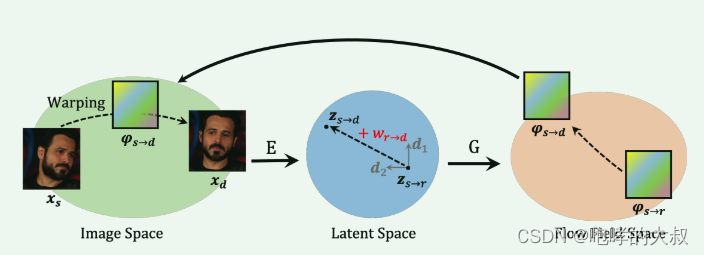
Lia 原理 2024-05-09 python, 机器学习, 深度学习, 人工智能, 神经网络 240人 已看 W_rd: driving image通过编码器E 映射成512维向量,然后通过MLP映射成20维视觉向量A_rd,与字典D中的向量结合得到w_rd,字典D包含了代表不同视觉变换的正交基,字典D是训练中学习得到的,每个向量有特定语意。若id不同,则采用relative transfer,即将第一帧与驱动帧(target)的变化差异施加到源帧(source)上,并且要求源人脸和第一帧的pose要相似。X_s (source image )映射到编码Z_sr,通过W_rd方向上的变化,得到新的编码Z_sd。
用于YouTube推荐的深度神经网络YouTube DNN 2024-05-06 机器学习, dnn, 深度学习, 人工智能, 神经网络 170人 已看 本文最突出的贡献在于如何结合业务实际和用户场景,选择等价问题,实现推荐系统。首先,深度协同过滤模型能够有效地吸收更多特征,并对它们与深度层的相互作用进行建模,优于以前在YouTube上使用的矩阵分解方法。其次,作者对特征的处理策略充满智慧。比如,对特征的加入,消除了对过去的固有偏见,并允许模型表示流行视频的时间依赖行为。最后,排序阶段,对评估指标的选择能够结合业务,取期望观看时间进行训练。
机器学习——2.损失函数loss 2024-05-06 python, 机器学习, 深度学习, 人工智能, 开发语言 133人 已看 损失函数就是计算预测结果和实际结果差距的函数,机器学习的过程就是试图将损失函数的值降到最小。
本地加载hugging face模型:Bert 2024-05-08 深度学习, 人工智能, 自然语言处理, bert 93人 已看 找了个hf的镜像站,把config.json和pytorch_model.bin两个文件进行下载下来,模型文件uncased_L-12_H-768_A-12.zip下载下来先。解压模型文件压缩包,把前面下载的两个文件也放进去,总共6个文件。BERT_PATH这里对应的文件路径。
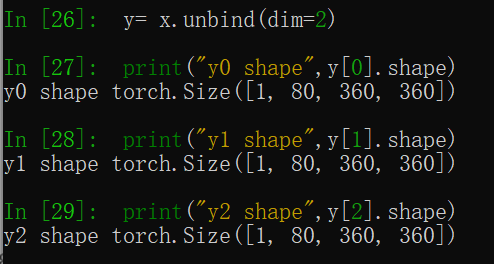
pytorch基础: torch.unbind() 2024-05-08 python, 机器学习, 深度学习, 人工智能, pytorch 139人 已看 【代码】pytorch基础: torch.unbind()
【神经网络】08 - 损失函数&反向传播 2024-05-01 机器学习, 深度学习, 人工智能, 神经网络 159人 已看 损失函数:在深度学习模型中,损失函数(Loss Function)是一种衡量模型预测与真实值之间差距的函数。换句话说,它是模型的性能指标。在训练过程中,我们的目标就是找到一组参数,它们可以最小化损失函数。常见的损失函数有均方误差(MSE, Mean Squared Error),交叉熵(Cross Entropy)等。我之前学的人工智能原理中的方差代价函数也属于这里的损失函数。
【神经网络】09 - 优化器 torch.optim 2024-05-02 机器学习, 深度学习, 人工智能, 神经网络 106人 已看 优化器是用于更新和管理模型参数以改进模型性能的一种工具。在机器学习和深度学习中,优化器的主要任务是通过调整模型的参数来最小化或最大化特定的目标函数。在许多情况下,这个目标函数是一个损失函数,我们的目标是将其最小化。在 PyTorch 中,torch.optim 是一个包含了各种优化算法的模块,用于帮助开发者在训练神经网络时更方便地更新和管理模型参数。当我们训练神经网络时,我们的目标是找到一组模型参数,可以最小化或最大化某个损失函数或者目标函数。