探索现代AI生成模型的底层原理:大语言模型、视频模型与图片模型 2024-05-21 语言模型, 音视频, 深度学习, 人工智能, 自然语言处理 342人 已看 现代AI生成模型在文本、图像、音频和视频等多个领域展现出了巨大的潜力。大语言模型、视频生成模型和图片生成模型的底层原理各具特色,但都基于深度学习和神经网络技术的发展。未来,随着技术的不断进步和跨领域融合,生成模型将为我们的生活和工作带来更多的便利和创意。与此同时,伦理和监管问题也需要得到重视,以确保AI技术的健康发展。
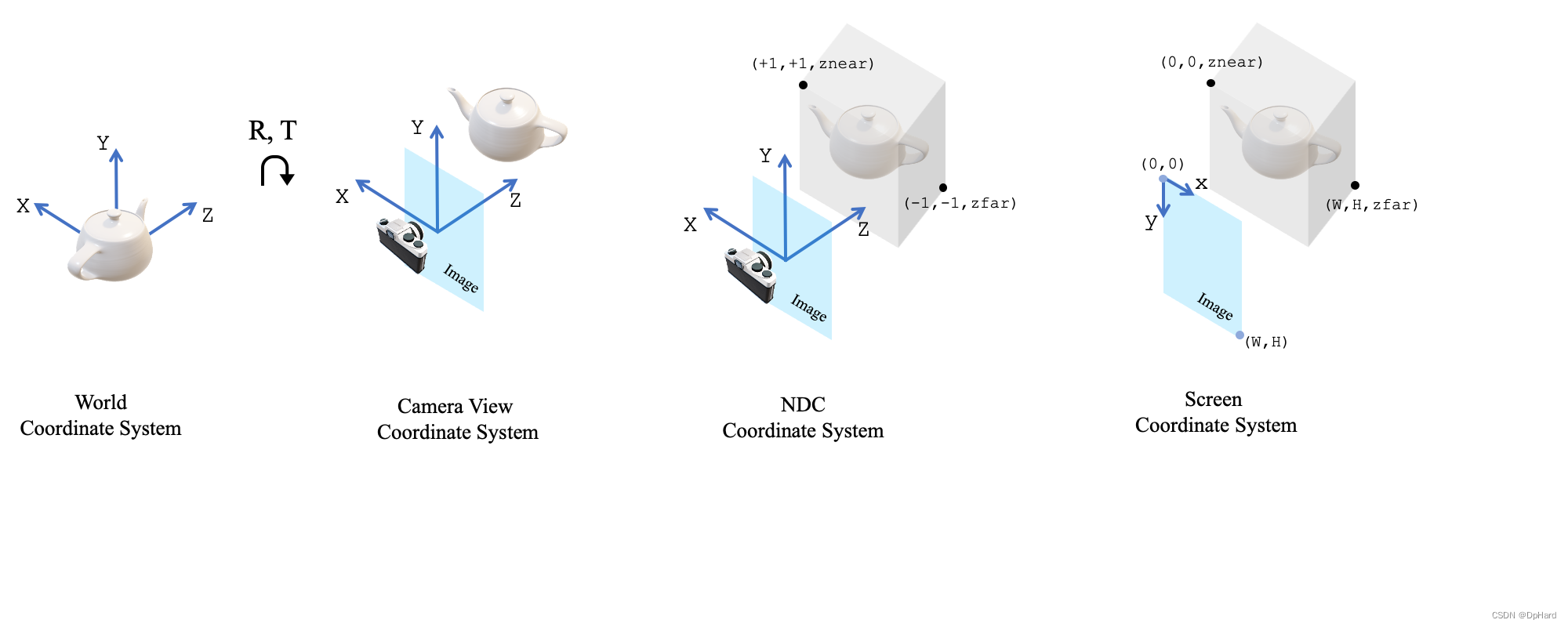
解析pytorch3D中的坐标变换问题 2024-05-18 3d, python, 深度学习, pytorch, 人工智能 381人 已看 借用pytorch3d官网对于坐标系的解释来讲,pytorch3d中使用了一个NDC坐标系,这个坐标系最终将所有3d点的坐标归一化到-1到1之间。熟悉pytorch的朋友应该知道这是为了方便梯度的反向传播。与常规的图形和视觉系统一致,我们分别定义了1、模型坐标系(可选,图中未显示)2、世界坐标系3、相机坐标系4、NDC坐标系5、屏幕坐标系其坐标轴的朝向如图所示。
Pytorch: 解决因pytorch版本不同 导致训练ckpt加载失败 2024-05-18 python, 机器学习, 深度学习, pytorch, 人工智能 361人 已看 在torch1.6版本及其以后,torch.save函数使用了一种新的文件格式。torch.load任然保持着对旧版本的兼容,如果高版本环境下想要保存低版本兼容的模型文件格式,可以使用_use_new_zipfile_serialization=False参数设定。大家都会遇到在工程项目实施阶段,如果训练的模型文件在不同的torch版本环境下部署时,会报错~。转载自SSDesign的知乎文章。
基于transformers框架实践Bert系列3-单选题 2024-05-17 深度学习, 人工智能, 自然语言处理, bert 180人 已看 本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、阅读理解、多选选择、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert等)本篇主要讲解应用场景。
深度学习模型keras第六讲:在TensorFlow中自定义fit()方法中的操作 2024-05-16 python, tensorflow, 深度学习, 人工智能, keras 369人 已看 TensorFlow允许开发者自定义fit()函数,以满足特定训练需求。通过自定义fit(),用户可以完全掌控训练循环,包括前向传播、损失计算、反向传播和参数更新。这种方式使得开发者能够灵活地调整学习率、添加自定义的回调函数,或实现特定的训练策略。自定义fit()还提供了更大的灵活性,比如在不同数据集上应用不同的训练方法,或在训练过程中动态地改变模型结构。通过编写自定义的fit()函数,开发者能够根据自己的需求构建更高效、更准确的深度学习模型。
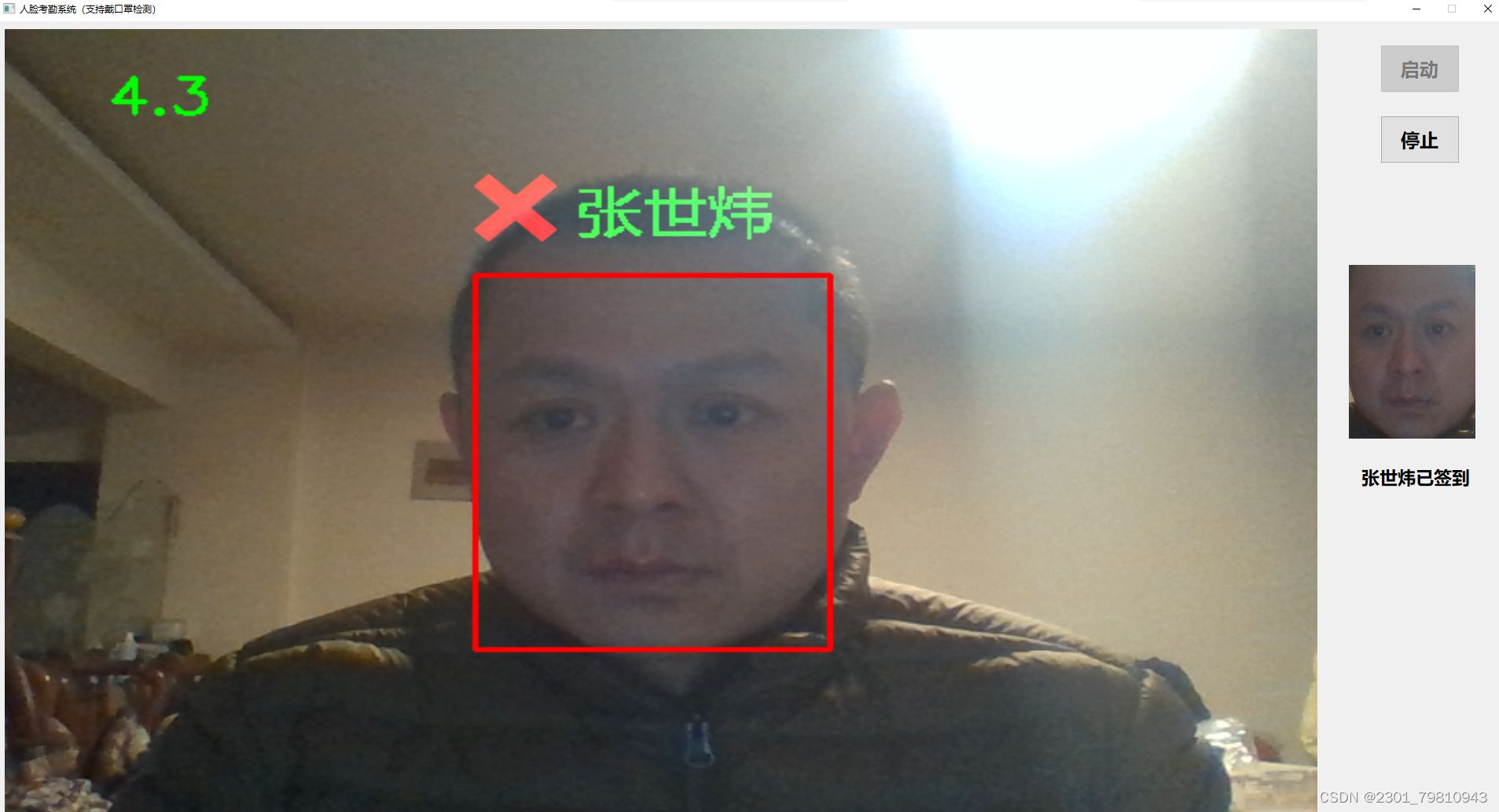
深度学习之基于Tensorflow卷积神经网络遮挡人脸识别考勤签到系统 2024-05-21 python, cnn, tensorflow, 深度学习, 人工智能 139人 已看 一、项目背景与目标随着深度学习技术的发展,人脸识别技术已广泛应用于各个领域。然而,在实际应用中,人脸遮挡问题常常给识别带来挑战。本项目旨在利用Tensorflow框架构建卷积神经网络(CNN),开发一个能够应对遮挡人脸识别的考勤签到系统,提高识别的准确性和鲁棒性。二、技术原理与特点Tensorflow框架:本项目采用Tensorflow深度学习框架,利用其强大的计算能力和灵活的编程接口,实现卷积神经网络的构建、训练和部署。卷积神经网络(CNN):CNN是一种特别适合处理图像问题的神经网络。
Stable Diffusion详解 2024-05-17 stable diffusion, 深度学习, 人工智能 95人 已看 定义UNet模型,用于逐步去噪图像。# 定义UNet的各个层次nn.ReLU(),nn.ReLU()nn.ReLU(),nn.Tanh()return x。
huggingface 笔记:聊天模型 2024-05-21 python, 笔记, 深度学习, 人工智能, pytorch 95人 已看 在原来生成的chat的基础上,追加一条消息,并将其传入pipeline。
基于transformers框架实践Bert系列1--分类器(情感分类) 2024-05-17 深度学习, 人工智能, 自然语言处理, bert 183人 已看 本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、机器阅读、多选选择、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert等)本篇主要讲解。
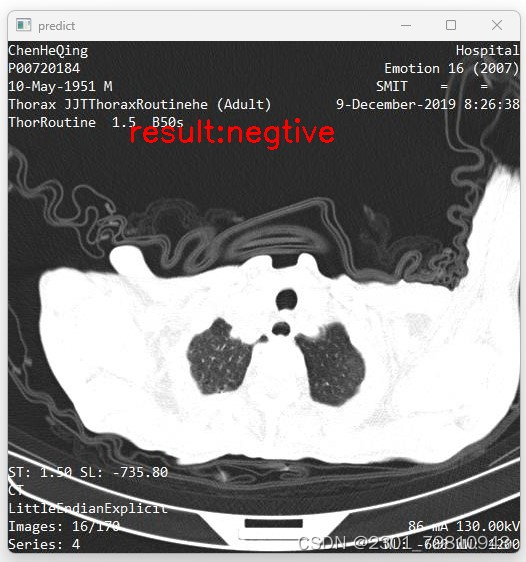
深度学习基于Tensorflow卷积神经网络VGG16的CT影像分类 2024-05-17 cnn, tensorflow, 深度学习, 人工智能, 分类 124人 已看 一、项目背景在医疗影像诊断领域,CT(Computed Tomography)影像因其高分辨率和三维成像能力,成为医生诊断疾病的重要工具。然而,人工分析大量的CT影像数据既耗时又容易出错。因此,开发自动的CT影像分类系统对于提高诊断效率、减少人为错误具有重要意义。本项目旨在利用深度学习技术,特别是基于TensorFlow框架的VGG16卷积神经网络模型,实现CT影像的自动分类。二、项目目标。
基于transformers框架实践Bert系列1--分类器(情感分类) 2024-05-17 深度学习, 人工智能, 自然语言处理, bert 171人 已看 本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、机器阅读、多选选择、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert等)本篇主要讲解。
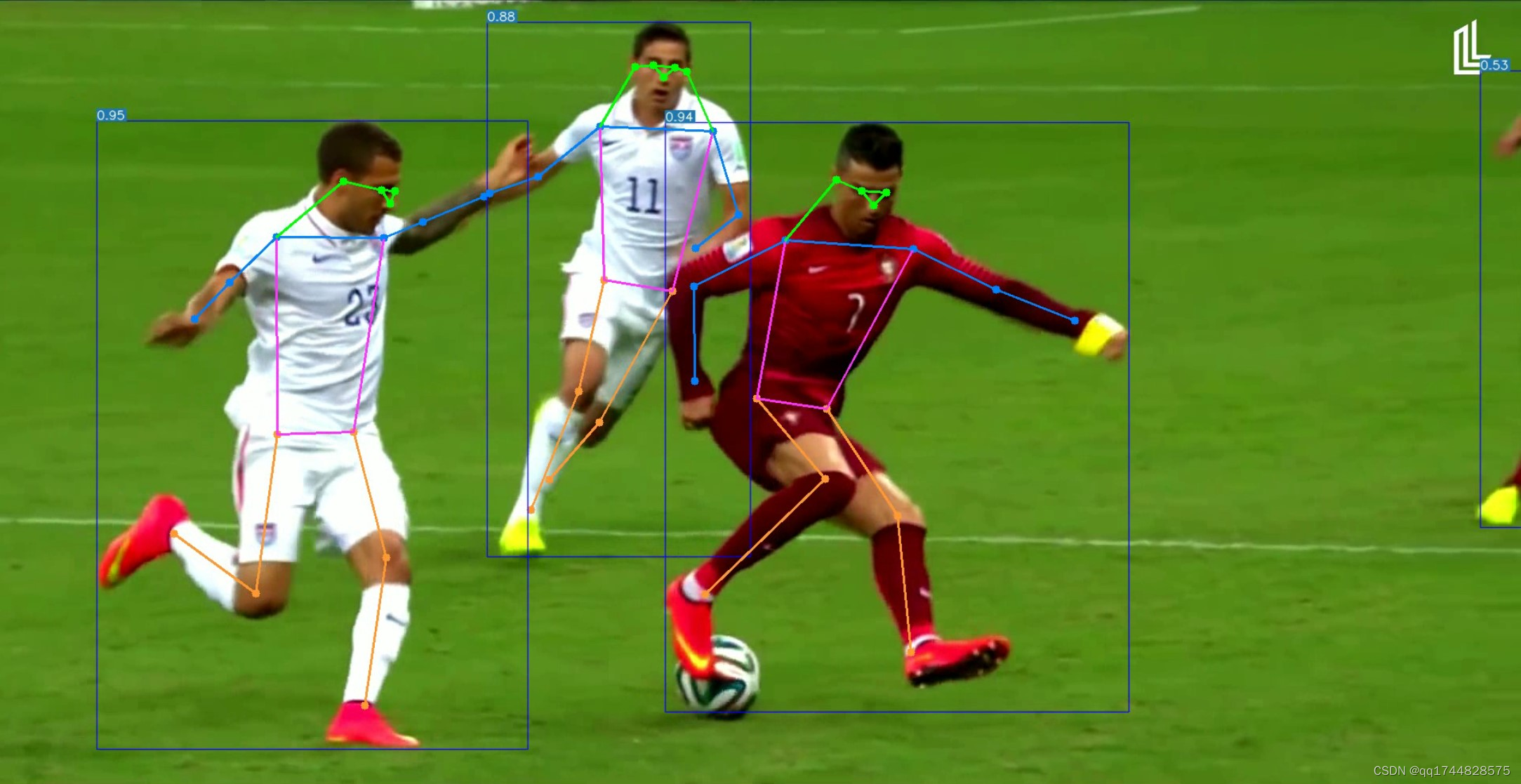
深度学习之基于YoloV7+OpenPose姿态识别系统 2024-05-17 yolo, 计算机视觉, 深度学习, 人工智能, 目标跟踪 273人 已看 一、系统背景随着深度学习技术的快速发展,其在计算机视觉领域的应用也日益广泛。姿态识别作为计算机视觉的一个重要分支,对于人机交互、运动分析、动作捕捉、虚拟现实等领域具有重要意义。YOLOv7和OpenPose作为两种先进的深度学习算法,分别在目标检测和人体姿态估计方面表现出色。因此,结合YOLOv7和OpenPose的优势,构建基于YOLOv7+OpenPose的姿态识别系统,具有广阔的应用前景。二、系统组成。
YOLOv8改进 | 卷积模块 | 用DWConv卷积替换Conv【轻量化网络】 2024-05-18 yolo, cnn, 深度学习, pytorch, 神经网络 829人 已看 YOLOv8改进,yolov8,yolov8创新,yolov8涨点
深度学习打卡实战第p7周咖啡豆识别 2024-05-17 深度学习, 人工智能 97人 已看 在训练模型时候,优化器选择adam,效果正常,测试集准确率可达99,而选用sgd时候,发现准确率恒定不变在22,查看了初始学习率为0.0001,修正为0.01,再次训练,效果较好。再次调回0.0001,不再固定,可能一开始陷入局部最优。整体训练效果较好,第一步使用pathlib查看类别名称验证能否与实际对应,使用imagefolder创建数据集,定义数据处理方式,然后可以.class查看分类,对数据集进行4:1划分,创建dataloder,到这里 数据集才算处理完成。
深度学习基于Tensorflow卷积神经网络VGG16的CT影像分类 2024-05-17 cnn, tensorflow, 深度学习, 人工智能, 分类 111人 已看 一、项目背景在医疗影像诊断领域,CT(Computed Tomography)影像因其高分辨率和三维成像能力,成为医生诊断疾病的重要工具。然而,人工分析大量的CT影像数据既耗时又容易出错。因此,开发自动的CT影像分类系统对于提高诊断效率、减少人为错误具有重要意义。本项目旨在利用深度学习技术,特别是基于TensorFlow框架的VGG16卷积神经网络模型,实现CT影像的自动分类。二、项目目标。
【实战】图像风格迁移:Keras和TensorFlow在风格迁移中的应用 2024-05-17 python, tensorflow, 深度学习, 人工智能, keras 333人 已看 风格迁移的概念最早由提出。该技术通过优化一个目标函数来实现,该函数由三部分组成:内容损失(content loss)、风格损失(style loss)和总变分损失(total variation loss)。内容损失确保生成的图像在内容上与原始图像相似。风格损失确保生成的图像在风格上与参考图像相似。总变分损失添加了一个正则项,以保持生成图像的局部空间连续性,从而提高其视觉质量。
[数据集][目标检测]抽烟喝酒检测数据集VOC+YOLO格式1026张2类别 2024-05-18 yolo, 机器学习, 深度学习, 目标检测, 人工智能 113人 已看 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:[“drinking”,“smoking”]图片数量(jpg文件个数):1026。标注数量(xml文件个数):1026。标注数量(txt文件个数):1026。使用标注工具:labelImg。标注规则:对类别进行画矩形框。