从零开始:腾讯云轻量应用服务器上部署MaxKB项目(基于LLM大语言模型的知识库问答系统) 2024-06-03 语言模型, 人工智能, 自然语言处理 88人 已看 MaxKB是基于LLM大语言模型的知识库问答系统,旨在成为企业的最强大脑。它支持开箱即用,无缝嵌入到第三方业务系统,并提供多模型支持,包括主流大模型和本地私有大模型,为用户提供智能问答交互体验和灵活性。
Keras深度学习框架实战(5):KerasNLP使用GPT2进行文本生成 2024-06-03 python, 深度学习, 人工智能, keras, 自然语言处理 233人 已看 本文是一个关于如何使用KerasNLP库加载、微调GPT-2模型并进行文本生成的教程。它先指导用户设置Colab的GPU加速环境,然后介绍KerasNLP库,包括其预训练模型和模块化构建块。教程展示如何加载GPT-2模型,并基于用户输入生成文本。还包括了一个使用Reddit数据集微调模型的示例,以及探讨了Top-K、Beam等采样方法,并演示了在中文诗歌数据集上微调模型。通过这些步骤和代码示例,用户可以学习如何使用KerasNLP和GPT-2模型完成多种文本生成任务。
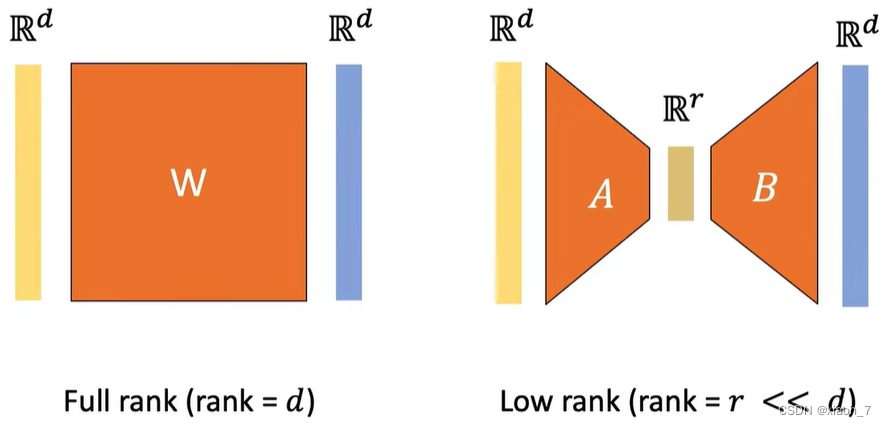
探索Lora:微调大型语言模型和扩散模型的低秩适配方法【原理解析,清晰简洁易懂!附代码】 2024-05-29 语言模型, 人工智能, 自然语言处理 169人 已看 Lora是一种创新且高效的微调大型模型的方法。通过低秩矩阵分解,Lora能够在保持模型性能的同时,显著减少计算资源和存储需求。本文介绍了Lora的背景、原理、公式、代码实现及其效果,希望能帮助你更好地理解和掌握这一方法。随着大型模型在各个领域的广泛应用,Lora的出现为我们提供了一种高效、实用的微调解决方案。
自然语言处理(NLP)—— C-value方法 2024-06-05 c语言, 人工智能, 自然语言处理 137人 已看 C-value方法是一种计算语料库中词组术语重要性的方法,最早由Frantzi、Ananiadou和Tsujii于1999年提出。这个方法特别适用于从大量文本数据中自动识别和评估潜在的术语或关键短语。其独特之处在于能够处理词组的包含和被包含关系,准确评估词组的重要性。首先,定义一个依赖于特定语言的、固定的词性标签模式集合。这些模式用于在语料库中匹配可能的术语候选词组。例如,在英语中,可以使用名词短语(NP)模式来识别候选词组。
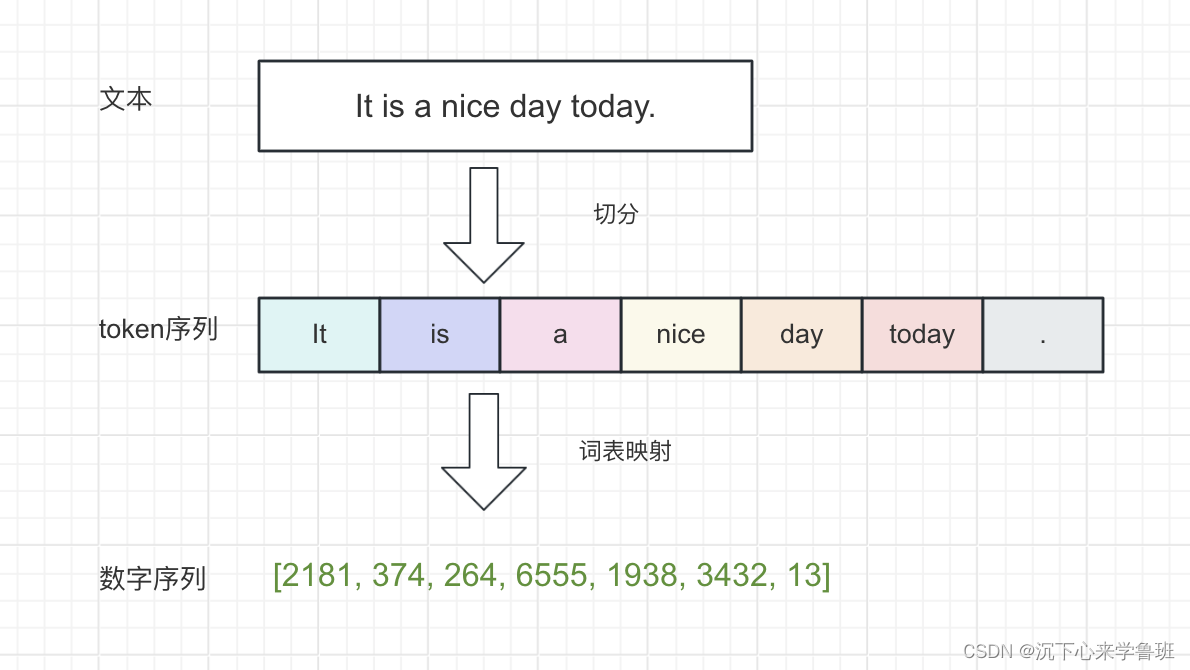
语言模型解构——Tokenizer 2024-05-31 c#, 语言模型, 人工智能, 自然语言处理, 开发语言 82人 已看 Tokenizer是一个词元生成器,它首先通过分词算法将文本切分成独立的token列表,再通过词表映射将每个token转换成语言模型可以处理的数字。
讲解如何使用RAG(检索增强生成)和LLM(大语言模型)来构建一个法律咨询网站。 2024-06-02 语言模型, 人工智能, 自然语言处理 95人 已看 文档预处理:将法律文档转化为向量,存储在Faiss向量数据库中。文档检索:根据用户问题检索相关文档。提取重要段落:从相关文档中提取与用户问题相关的重要段落。生成答案:使用OpenAI的GPT-4生成详细回答。前后端构建:使用Flask构建后端API,用HTML和JavaScript构建简单的前端页面。通过这些步骤,即使是初学者也能逐步理解和实现一个利用RAG+LLM技术的法律咨询网站。
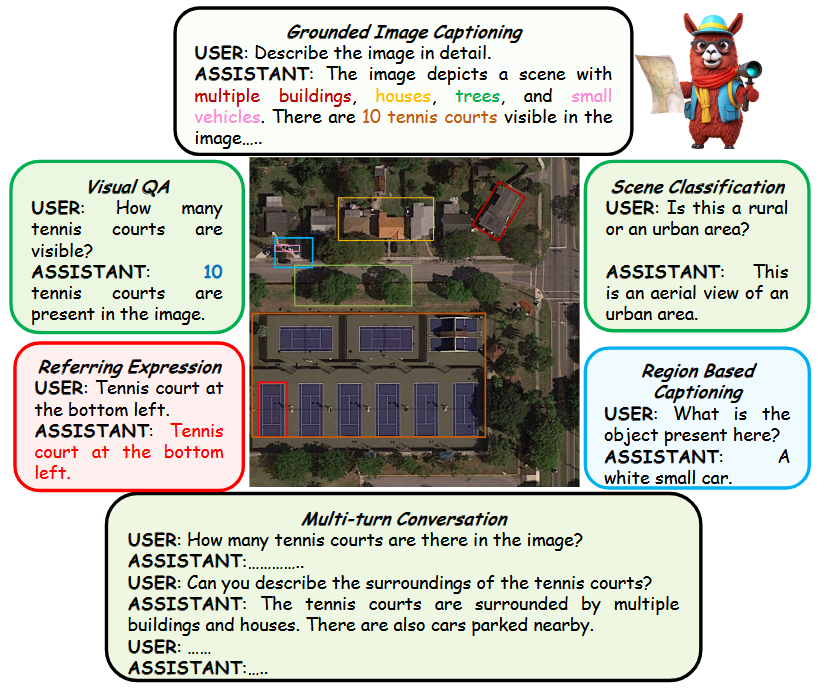
【论文阅读】遥感大模型GeoChat : Grounded Large Vision-Language Model for Remote Sensing 2024-06-02 论文阅读, 语言模型, 人工智能, 自然语言处理 436人 已看 本文是遥感领域的大模型相关的一篇工作,发表在CVPR2024。
大语言模型技术系列讲解:大模型应用了哪些技术 2024-05-31 语言模型, 人工智能, 自然语言处理 70人 已看 为了弄懂大语言模型原理和技术细节,笔者计划展开系列学习,并将所学内容从简单到复杂的过程给大家做分享,希望能够体系化的认识大模型技术的内涵。本篇文章作为第一讲,先列出大模型使用到了哪些技术,目的在于对大模型使用的技术有个整体认知。后续我们讲一一详细讲解这些技术概念并解剖其背后原理。大语言模型(LLMs)在人工智能领域通常指的是参数量巨大、能够处理复杂任务的深度学习模型。大模型通常是深度神经网络的一种,具有多层结构,能够学习数据的复杂表示。
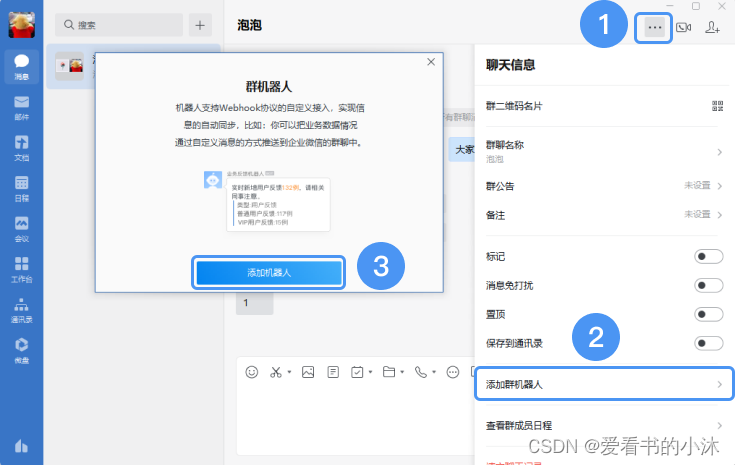
【NLP开发】Python实现聊天机器人(微信机器人) 2024-06-01 人工智能, 自然语言处理 100人 已看 通过腾讯云HiFlow场景连接器,可以零代码的设置企业微信机器人自动/定时发消息的规则,比如:每周五下午6点定时发送周报;收到新的销售线索/报表自动发送消息通知管理群等。
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.04.20-2024.04.25 2024-05-30 语言模型, 人工智能, 自然语言处理 113人 已看 使用检索增强生成(RAG)从外部知识源检索相关信息,可以让大型语言模型(LLM)回答私人和/或以前未见过的文档集合中的问题。但是,RAG 无法回答针对整个文本语料库的全局性问题,例如 “数据集中的主要主题是什么?”,因为这本质上是一个以查询为重点的总结(QFS)任务,而不是一个明确的检索任务。同时,先前的 QFS 方法无法扩展到典型 RAG 系统索引的文本数量。
Transformers x SwanLab:可视化NLP模型训练 2024-05-28 人工智能, 自然语言处理 94人 已看 HuggingFace 的 Transformers 是目前最流行的深度学习训框架之一(100k+ Star),现在主流的大语言模型(LLaMa系列、Qwen系列、ChatGLM系列等)、自然语言处理模型(Bert系列)等,都在使用Transformers来进行预训练、微调和推理。
【sklearn | 3】时间序列分析与自然语言处理 2024-05-31 easyui, python, 人工智能, sklearn, 自然语言处理 137人 已看 通过本篇进阶教程,我们学习了 sklearn 中的时间序列分析和自然语言处理的基本方法。时间序列分析包括特征提取、时间序列拆分和预测模型,而自然语言处理涵盖了文本特征提取和文本分类。希望这些知识能在你的实际项目中有所帮助,并激发你进一步探索更复杂的时间序列和自然语言处理技术。
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.01-2024.05.10 2024-05-28 语言模型, 计算机视觉, 深度学习, 人工智能, 自然语言处理 120人 已看 医学图像识别任务因存在多种不同的病理指征而明显复杂化,这给未见标签的多标签分类带来了独特的挑战。这种复杂性凸显了对采用多标签零点学习的计算机辅助诊断方法的需求。预训练视觉语言模型(VLMs)的最新进展展示了医疗图像零镜头分类的显著能力。然而,这些方法在利用来自更广泛图像数据集的大量预训练知识方面存在局限性,而且通常依赖于放射科专家的手动提示构建。通过自动调整提示过程,提示学习技术已成为使 VLM 适应下游任务的有效方法。
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.10-2024.05.20 2024-05-28 语言模型, 人工智能, 自然语言处理 68人 已看 编辑视频时,一段动听的背景音乐必不可少。然而,视频背景音乐生成任务面临着一些挑战,例如缺乏合适的训练数据集,难以灵活控制音乐生成过程并按顺序对齐视频和音乐。在这项工作中,我们首先提出了一个高质量的音乐视频数据集 BGM909,该数据集具有详细的注释和镜头检测功能,可提供视频和音乐的多模态信息。然后,我们提出了评估音乐质量的评价指标,包括音乐多样性和音乐与视频之间的匹配度以及检索精度指标。
LLM大语言模型学习资料网站(git、gitee、等) 2024-05-30 学习, git, 语言模型, 人工智能, 自然语言处理 144人 已看 LLM的火爆程度不用多说,如果想深入理解大语言模型(LLM),一些必要的论文还是要读的。以下是汇总的LLM大语言模型学习资料网站(Git、Gitee、模型社区等)
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.05.01-2024.05.05 2024-05-30 语言模型, 人工智能, 自然语言处理 81人 已看 虽然大型语言模型(LLMs)作为交互任务中的代理已显示出巨大的前景,但其巨大的计算需求和有限的调用次数限制了其实际效用,特别是在决策等长时交互任务或涉及持续不断任务的场景中。为了解决这些制约因素,我们提出了一种方法,将拥有数十亿参数的 LLM 的性能转移到更小的语言模型(7.7 亿参数)中。我们的方法包括构建一个由规划模块和执行模块组成的分层代理,规划模块通过从 LLM 中进行知识提炼来生成子目标,而执行模块则通过学习使用基本动作来完成这些子目标。
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.05.10-2024.05.20 2024-05-29 语言模型, 人工智能, 自然语言处理 73人 已看 预训练+微调范式是在各种下游应用中部署大型语言模型(LLM)的基础。其中,Low-Rank Adaptation(LoRA)因其参数高效微调(PEFT)而脱颖而出,产生了大量现成的针对特定任务的 LoRA 适配程序。然而,这种方法需要明确的任务意图选择,这给推理过程中的自动任务感知和切换带来了挑战,因为现有的多个 LoRA 适配程序都嵌入了单个 LLM 中。在这项工作中,我们介绍了 MeteoRA(多任务嵌入式 LoRA),这是一个专为 LLM 设计的可扩展多知识 LoRA 融合框架。
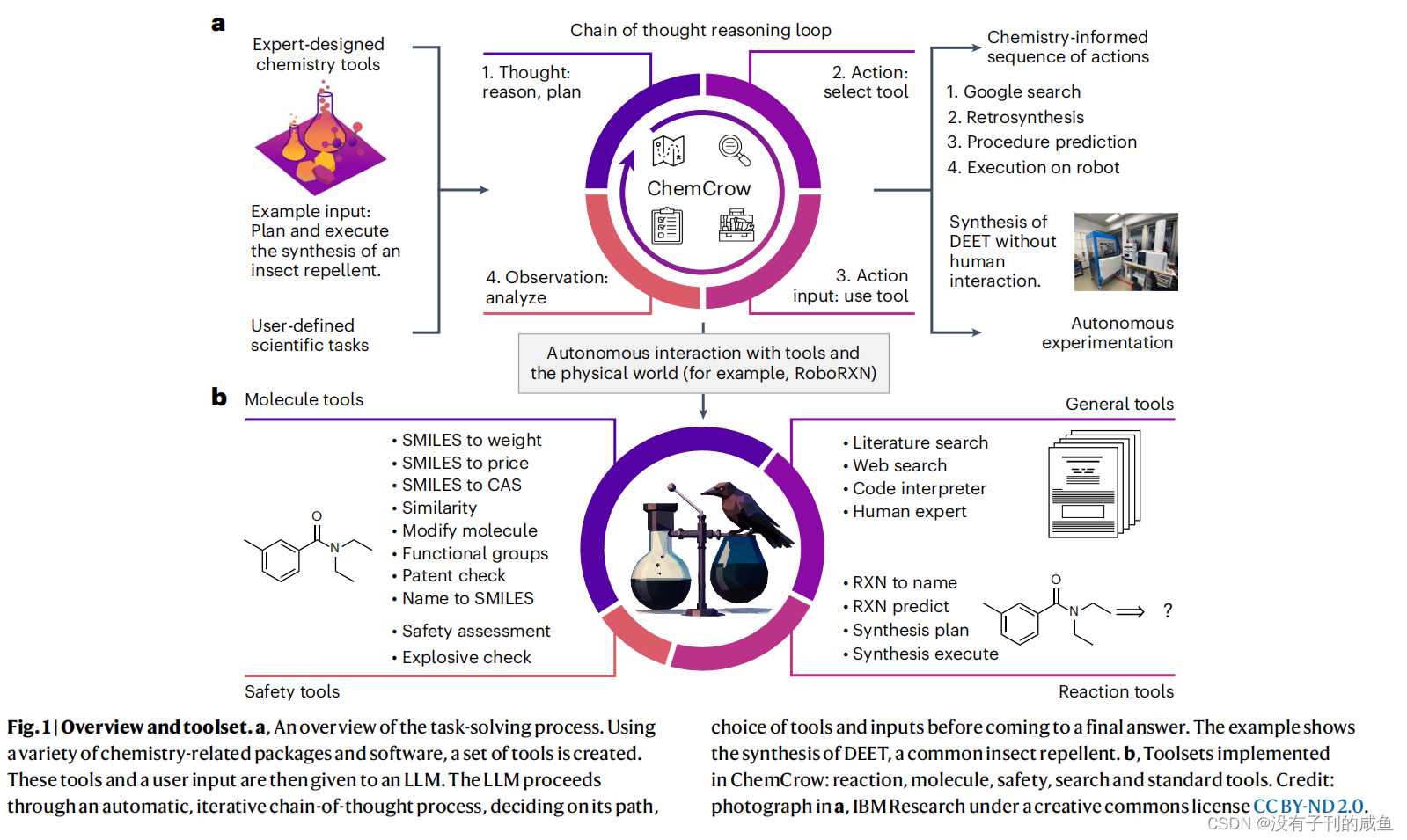
论文阅读笔记(十二)——Augmenting large language models with chemistry tools 2024-05-30 论文阅读, 笔记, 语言模型, 人工智能, 自然语言处理 162人 已看 大型语言模型(LLMs)在跨领域任务中表现出色,但在化学相关问题上却表现不佳。这些模型也缺乏外部知识源的访问权限,限制了它们在科学应用中的有用性。我们介绍了ChemCrow,这是一种设计用于完成有机合成、药物发现和材料设计任务的LLM化学代理。通过集成18个专家设计的工具,并使用GPT-4作为LLM,ChemCrow增强了LLM在化学领域的性能,并展现了新的能力。我们的代理自主规划和执行了昆虫驱避剂和三种有机催化剂的合成,并指导发现了一种新的发色团。