大数据——Spark 2024-05-28 spark, 分布式, 大数据 103人 已看 MLlib是Spark的机器学习()库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。2.
LAMP集群分布式安全方案 2024-05-29 安全, 分布式 54人 已看 LAMP(Linux + Apache + MySQL + PHP)是一种常见的Web应用程序堆栈,而LAMP集群是将多个服务器组合在一起以提供高可用性和可扩展性的解决方案。1. 评估集群环境下的数据安全性:通过配置和测试LAMP集群中的数据库服务器、Web服务器和应用服务器之间的安全连接,以确保数据传输的机密性和完整性。总之,LAMP集群式安全方案的实验目的是评估和增强LAMP集群的安全性、可靠性和鲁棒性,以应对潜在的安全威胁和故障情况。输入命令vi /etc/selinux/config,将。
聊聊几种常见的分布式Session解决方案 2024-05-26 分布式 46人 已看 highlight: xcodetheme: vuepress问题引入:什么是分布式Session?分布式 Session 是指在多台服务器之间共享和管理用户的会话数据,使得用户的会话状态能够在不同的服务器上保持一致。这样,无论用户的请求被路由到哪台服务器,都能够访问到相同的会话信息,从而保证用户体验的一致性。回顾一下单机服务的 HttpSession 的存储:在传统的 J...
kafka-守护启动 2024-05-29 kafka, 分布式 65人 已看 这里可以直接使用zookeeper-server-start.sh命令没有加 /opt/kafka/bin是因为本人已将kafka加入到系统bin命令下配置,已经配置了全局环境变量,实现处处都可以直接使用kafka命令
pyspark==windows单机搭建 2024-05-28 spark, 分布式, 大数据 109人 已看 下载安装hadoop-3.3.5并完整替换bin目录,配置HADOOP_HOME。下载安装JDK17,配置JAVA_HOME。下载spark配置SPARK_HOME。注意要指定python的地址。
WPF 如何调试 2024-05-28 hadoop, wpf, 分布式, 大数据 137人 已看 如果您使用的是 Visual Studio 的较旧选项,则无法使用此工具,但是还有另一个可以与 Visual Studio 集成的工具,例如 XAML Spy for Visual Studio .如果它不工作,然后检查什么是错的。在这些工具的帮助下,XAML 代码以正在运行的 WPF 应用程序的可视化树以及树中不同的 UI 元素属性的形式呈现。两个文本块的文本属性被静态设置为“姓名”和“职务”,而其他两个文本块的文本属性绑定到“名字”和“职务”,但类变量是 Employee 类中的名称和职务,如下所示。
详解 Spark 核心编程之 RDD 序列化 2024-05-31 spark, 分布式, 大数据 66人 已看 参考地址:https://github.com/EsotericSoftware/kryo。自定义 Kryo 序列化。
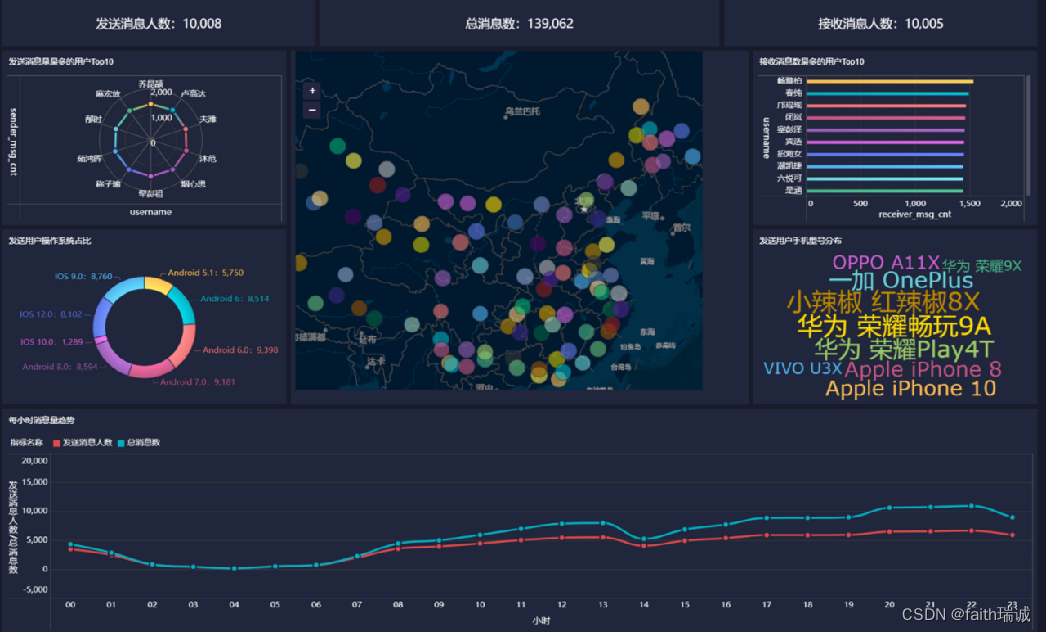
Hadoop+Hive数据分析综合案例 2024-05-31 hive, 数据分析, hadoop, 分布式, 大数据 165人 已看 聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。我们将基于一个社交平台App的用户数据,完成相关指标的统计分析并结合BI工具对指标进行可视化展现。
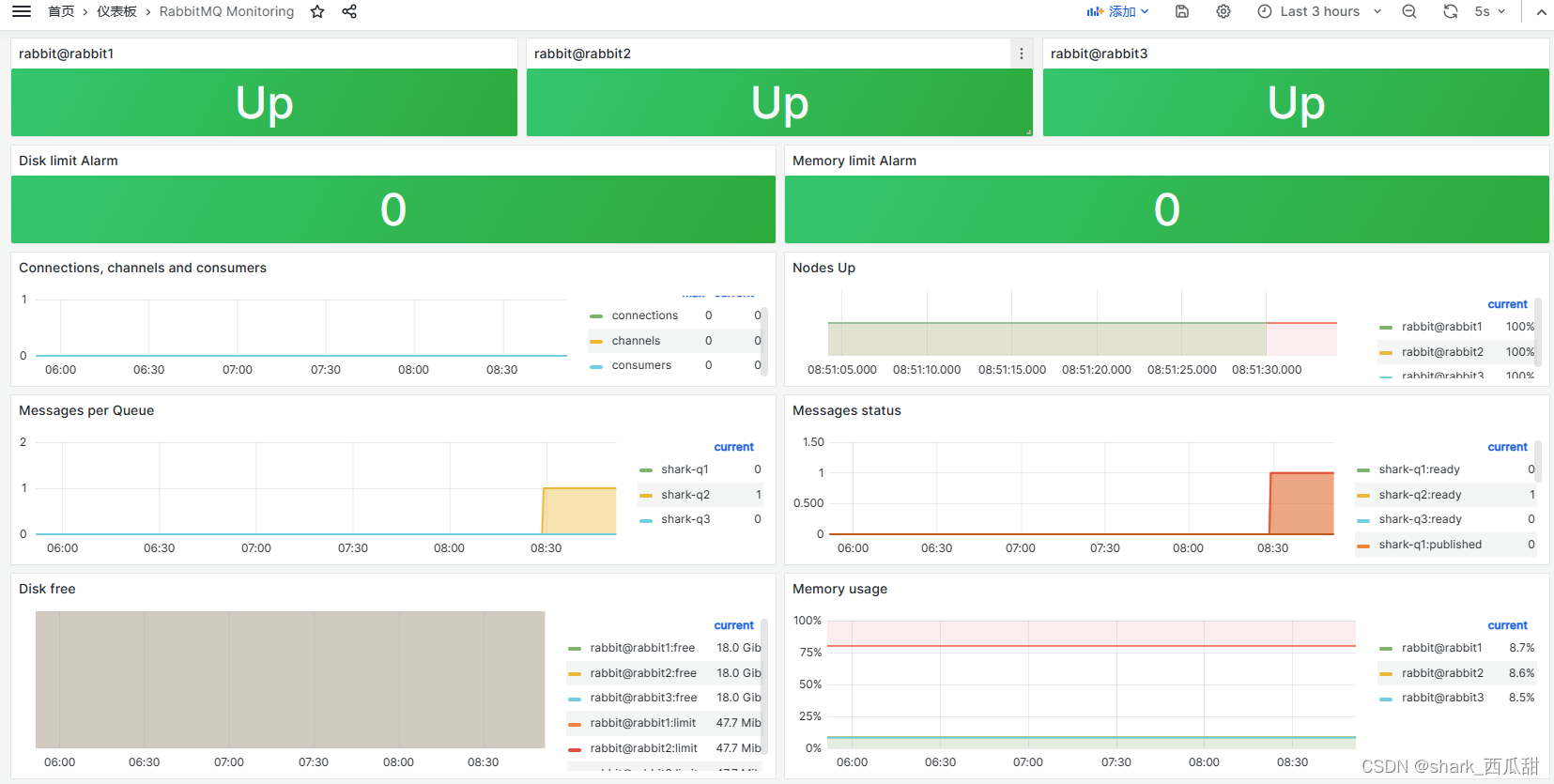
16-云原生监控体系-rabbitmq_exporter监控 RabbitMQ-[部署&Dashborad&告警规则实战] 2024-05-28 云原生, dash, rabbitmq, 分布式 187人 已看 下载地址 https://github.com/kbudde/rabbitmq_exporter/releases 中有适合各种平台的版本。如果选择使用 json 格式的配置文件进行配置,那需要给配置文件中出现的所有 key 配置值,因为没有默认值。github 地址 https://github.com/kbudde/rabbitmq_exporter。所有 metrics(golang/prometheus 除外)都以。可以是 json 格式的配置文件,也可以使用。风格的文件进行配置。
Kafka系列之高频面试题 2024-05-27 kafka, 分布式 62人 已看 简介、应用场景、概念、负载均衡与故障转移、分区、ACK、不丢失、去重、幂等性、有序性、消费者(再均衡、消费者组协调器、消费者和消费者组的关系)、与其他MQ中间件的比较、Kafka对比Pulsar、offset、Topic、删除Topic流程、ZooKeeper、Pull还是Push、消息事务、脚本、工具、配置、Broker、缺点;批处理、吞吐量、零拷贝、消息格式、文件存储、多租户、监控(指标、方案、工具)、安全
Spark-Shell使用Scala的版本 2024-05-31 scala, spark, 分布式, 大数据, 开发语言 242人 已看 在Spark-Shell中使用的Scala版本取决于你安装的Spark版本。这些技术细节共同构成了Spark大数据处理框架的核心能力和优势,使得Spark在大数据处理和分析领域得到了广泛的应用。
RabbitMQ 2024-05-30 rabbitmq, 分布式 68人 已看 持久化Exchange要持久化Queue 要持久化Message 要持久化生产方 确认confirm消费方 确认ack消息丢失 死信队列(死信交换机)Broker高可用(集群)
Docker安装Zookeeper(单机) 2024-05-30 云原生, zookeeper, 运维, debian, 分布式 206人 已看 restart always #始终重新启动zookeeper,看需求设置不设置自启动。-e TZ=“Asia/Shanghai” # 指定上海时区。-v # 将本地目录(文件)挂载到容器指定目录;-p 2181:2181 # 对端口进行映射。–name # 容器名称。-d # 后台运行容器。
如何查看Kafka数据文件中的 .log .index .timeindex 文件内容 2024-05-27 kafka, 数据库, 分布式 80人 已看 这些文件共同作用,确保 Kafka 能够高效、可靠地存储和检索消息数据。Kafka 的数据文件存储在每个分区的目录中,这些文件包括。
kafka单机安装及性能测试 2024-05-29 kafka, 分布式 73人 已看 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,并于2011年开源,随后成为Apache项目。Kafka的核心概念包括发布-订阅消息系统、持久化日志和流处理平台。它主要用于构建实时数据管道和流处理应用,广泛应用于日志聚合、数据传输、实时监控和分析等场景。Kafka具有高吞吐量、低延迟、扩展性强和容错性高等特点。
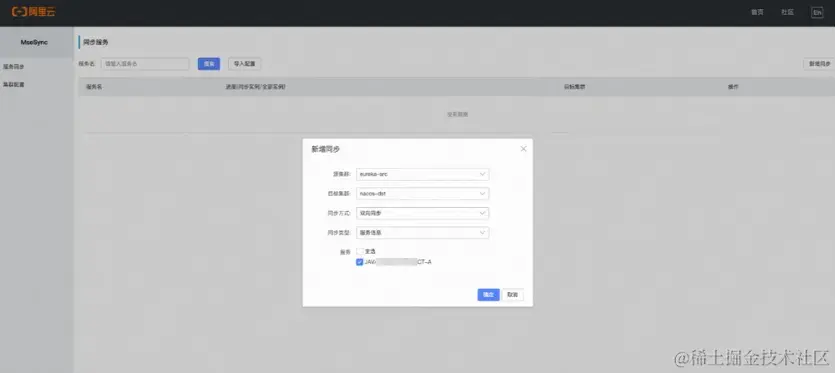
满帮集团 Eureka 和 ZooKeeper 的上云实践 2024-05-27 云原生, zookeeper, eureka, 分布式 192人 已看 在此次迁移过程中,业务能够平稳无损迁移和性能的大幅提升,证明了 MSE 在服务注册中心领域的卓越性能和可靠性。相信随着 MSE 的不断演进,其对易用性和稳定性的持续追求无疑将为更多企业带来巨大的商业价值,并在企业数字化进程中发挥越来越重要的作用。
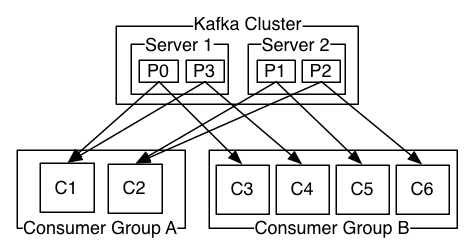
Kafka 2024-05-27 kafka, 分布式 63人 已看 它可以看作是一个消息队列服务,但与传统消息队列相比,具有更高的吞吐量、更好的可扩展性和持久性。(Kafka Cluster):这相当于广播电台的设施,包括发射塔、控制室等。(Consumers):消费者就是听众,也是信息的接收者。在Kafka中,消费者是指那些从。,不同的分区可以分布在Kafka集群的不同服务器上,以提高系统的吞吐量和可用性。为了通俗地理解Kafka,我们可以把它比作一个“大型的广播电台”,在Kafka中,消息是由生产者发布,消费者读取的。在Kafka中,消息被分类存储在不同的主题中,
如何修改 Kafka 消息保留时长:经验总结 2024-05-28 c#, linq, kafka, 分布式 124人 已看 Apache Kafka 是一种高性能的分布式消息系统,用于处理实时数据流。在实际使用中,我们可能需要根据业务需求调整 Kafka 消息的保留时长。本文将介绍如何修改 Kafka 消息保留时长,并分享在实际操作中的一些经验。修改 Kafka 消息保留时长是优化 Kafka 系统性能和资源使用的重要手段。通过合理的配置,可以满足不同业务场景的需求,同时确保系统的稳定性和高效性。希望本文的介绍和经验总结能帮助你更好地管理 Kafka 集群,提升业务处理能力。