python实现——分类类型数据挖掘任务(图形识别分类任务) 2024-05-31 算法, 机器学习, 人工智能, 数据挖掘, 分类 97人 已看 岩石种类有砾岩(Conglomerate)、安山岩(Andesite)、花岗岩(Granite)、石灰岩(Limestone)、石英岩(Quartzite)和5种,每种岩石图片各50张,共250张。定义:数据增强是利用现有数据生成新的数据来增加数据量的过程,能够有效地扩充训练数据集的大小,提高模型的泛化能力,同时也能够有效地防止过拟合现象的发生。注意自己python代码的文件引入路径(确保对应的路径下有对应的文件,我这里设置的是根目录下)使用save函数对训练好的模型进行保存,方便后续使用。
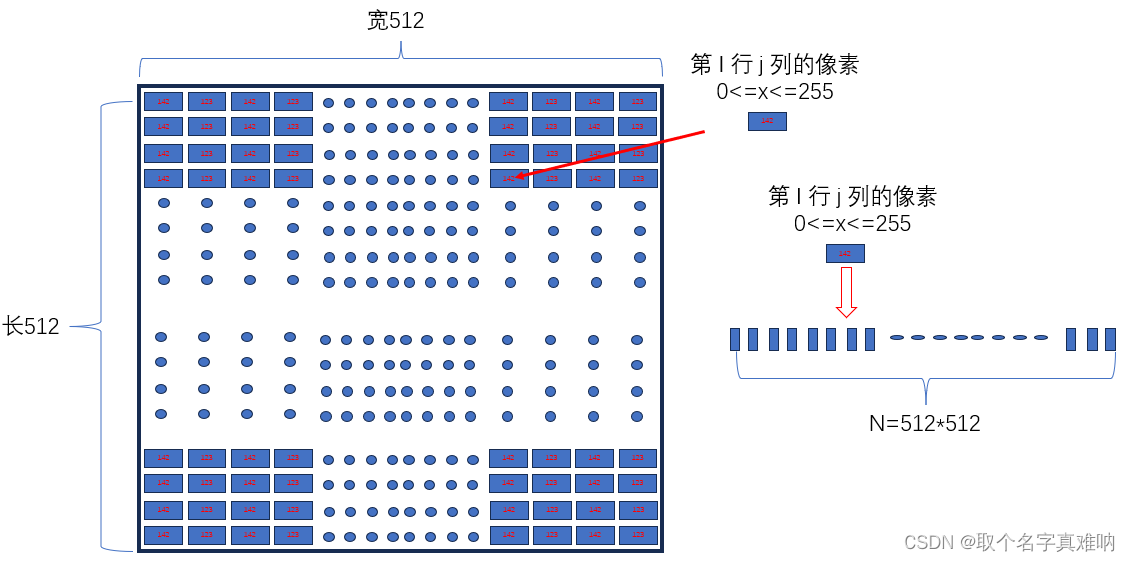
32. 基变换,图像压缩 2024-05-28 算法, 机器学习, 人工智能 38人 已看 本节主要内容是关于基变换的,从一组基变换到另外一组基中,这是在实际应用中会遇到,我们会在项目中讲到因为基的变换而引申出来的信号压缩,图像压缩问题。本章的主题是线性变换与矩阵的关联,线性变换不一定是在坐标系中进行变换,矩阵用坐标来表示线性变换,图像压缩也存在基的变换。我们平常收到的视频图像是非常大的,我们在传输过程中不可能将原始图像进行传输,这样对于网络的负载太大了,我们需要将图像进行压缩打包后再发送,最后在我们显示的时候解压缩进行图像的还原,这样我们就能够高效的进行图像的传递和播放。
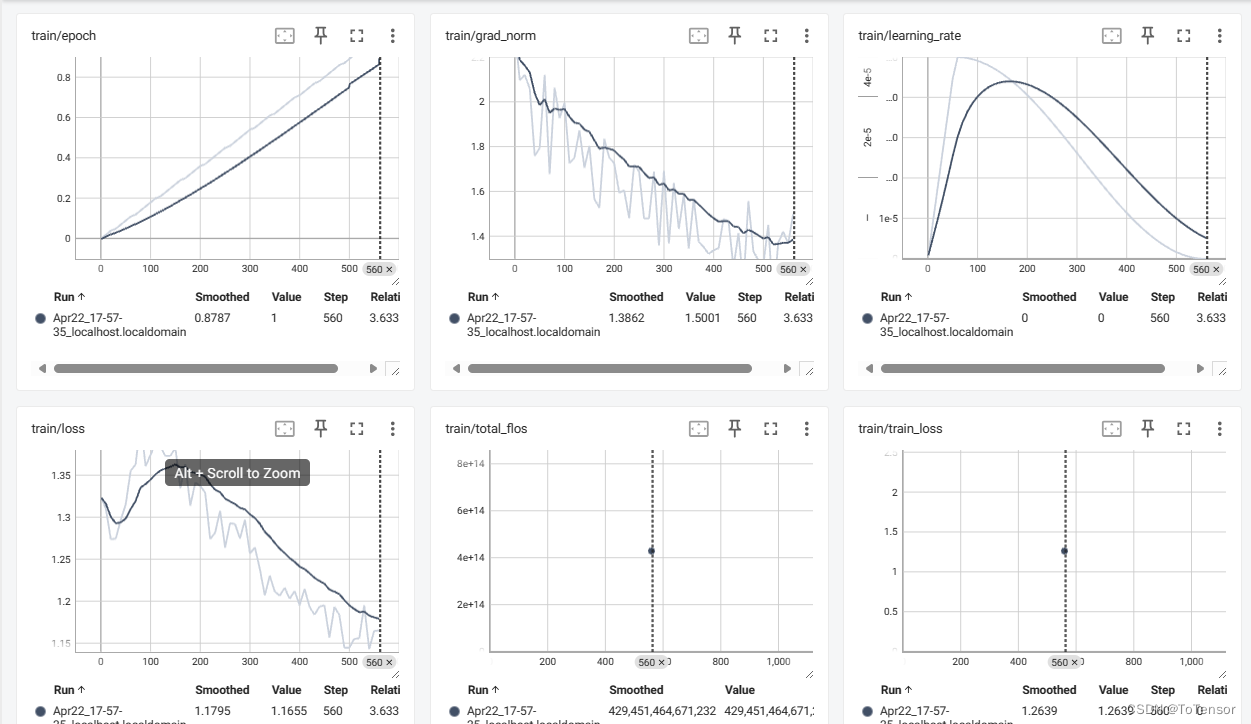
垂域LLM训练经验之谈 2024-06-01 算法, 机器学习, 深度学习, 人工智能, 神经网络 94人 已看 全参 SFTLora SFTLora 继续预训练Llama pro 预训练 + SFT预训练数据:由SFT数据的Query 与 Answer 的拼接SFT数据:由GPT4根据垂域文档抽取问答对+人工挑选而来,大概20000条,其中包括公司的介绍自我认知数据:大概200条,从公开的自我认知数据整理而来匠数科技大模型sft数据集显卡训练框架基座模型Qwen1.5-7B1、全参微调学东西最快2、lora要学习垂域知识,得多训几个epoch才行,或者对数据集进行过采样。
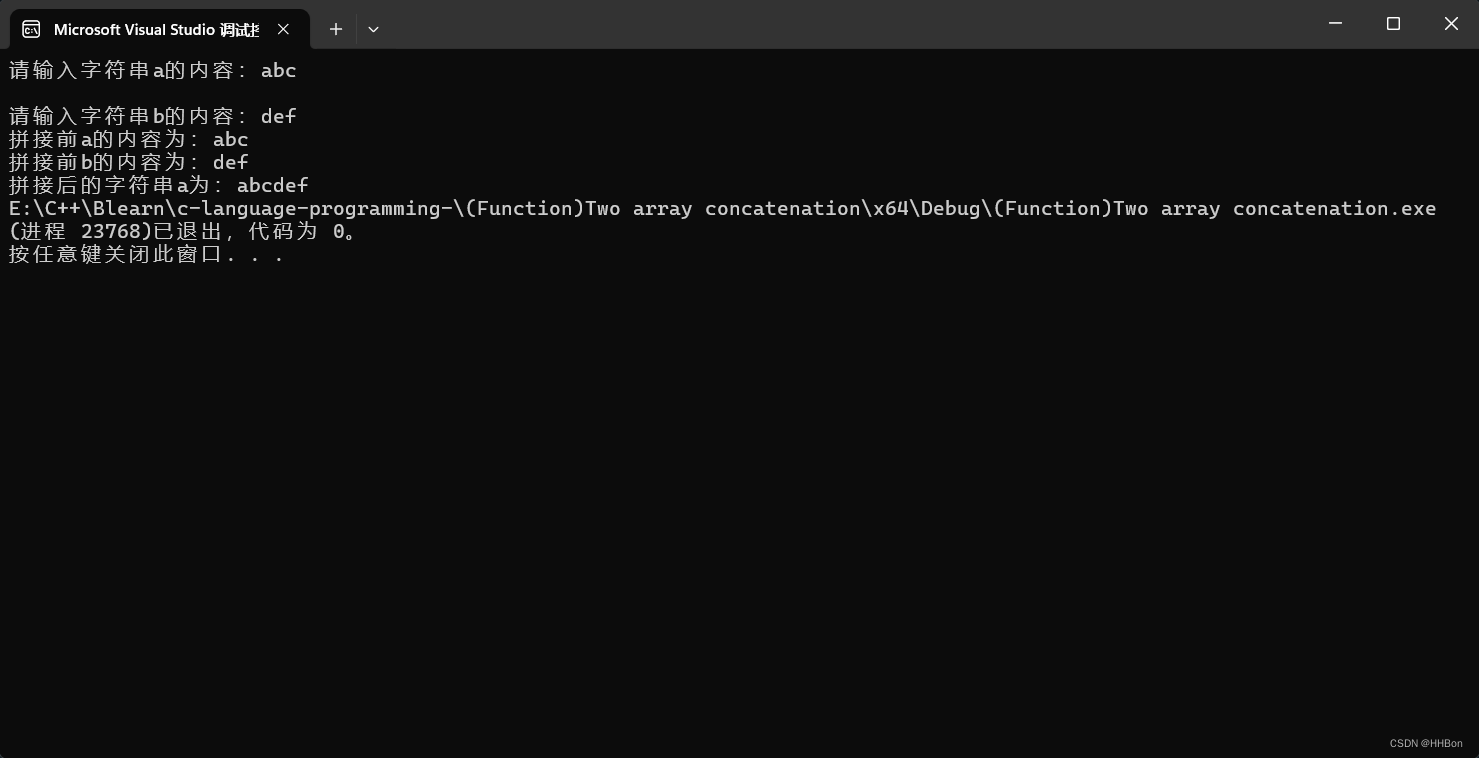
Java排序算法(一):冒泡排序 2024-05-31 算法, java, 排序算法, 数据结构, 开发语言 70人 已看 冒泡排序的基本思想是,对相邻的元素进行两两比较,顺序相反则进行交换,这样,每一趟会将最小或最大的元素“浮”到顶端,最终达到完全有序。
数据挖掘与机器学习——分类算法 2024-05-28 算法, 机器学习, 人工智能, 数据挖掘, 分类 112人 已看 1.回归 2.分类。机器学习算法最普通分类:分类算法的定义:分类算法的应用:分类器实现分类:分类器的构建标准:概率模型:贝叶斯公式:朴素贝叶斯算法(朴素贝叶斯分类器):案例:注意:python实现:KNN算法空间向量模型:KNN的定义:案例:
LeeCode热题100(两数之和) 2024-05-31 算法, leetcode, 职场和发展 91人 已看 我认为你要是没有思路的话,不妨暴力求解(没有暴力解决不了的),然后再看能不能优化一下,对吧。简单来说就是让你在一个数组里面找两个数,这两个数的和必须满足等于目标值target才行。假设target=20,nums数组的数为:4,6,13,8,7,9。本文纯干货,看不懂来打我!自己先去看一下第一题的题目。,value是数字对应的。i 先指向第一个数字4。
【算法模板】图论:最近公共祖先(LCA) 2024-05-29 算法, 图论 74人 已看 最近公共祖先(Lowest Common Ancestor,简称LCA)问题通常出现在树或图的结构中,特别是在计算机科学和算法领域。这个问题的核心是找到两个节点在树中的共同祖先,且这个祖先的深度(或者说高度)是最小的。
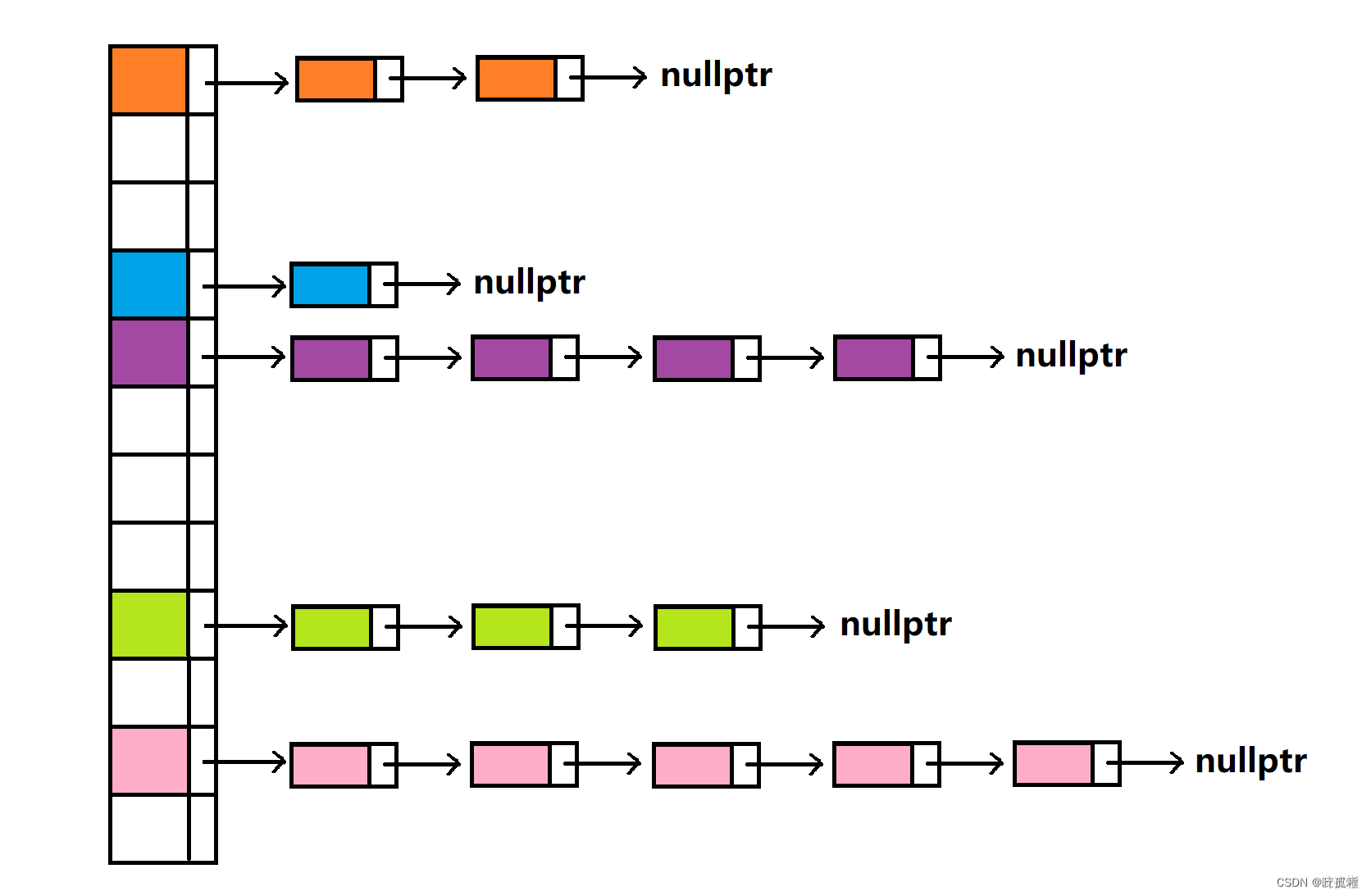
【C++】数据结构:哈希桶 2024-05-28 算法, c++, 哈希算法, 数据结构, 开发语言 159人 已看 哈希桶(Hash Bucket)是哈希表(Hash Table)实现中的一种数据结构,用于解决哈希冲突问题。哈希表是一种非常高效的数据结构,它通过一个特定的函数(哈希函数)将输入数据(通常是键,key)直接映射到一个数组的某个位置上,这样就可以通过这个位置快速访问到相应值(通常是值,value)。然而,不同的键可能经过哈希函数计算后得到相同的索引,这种现象称为哈希冲突。处理哈希冲突的方法有多种,其中开放地址法、链地址法和建立公共溢出区等,而哈希桶就是链地址法的具体应用。
数据结构的希尔排序(c语言版) 2024-05-28 算法, java, c语言, 数据结构, 排序算法 115人 已看 希尔排序是一种基于插入排序算法的优化排序方法。它的基本思想如下:选择一个增量序列 t1,t2,......,tk,其中 ti > tj, 当 i < j,并且 tk = 1。2.希尔排序的优点时间复杂度较低。希尔排序的时间复杂度一般在 O(n^1.25) 和 O(n^1.5) 之间,优于简单的插入排序。在部分有序的数组中效率很高。希尔排序通过分组插入排序来利用数据的局部有序性,可以有效地加快排序速度。空间复杂度低,只需要常量级的额外空间。代码实现相对简单,易于理解和编码。3.希尔排序的缺点。
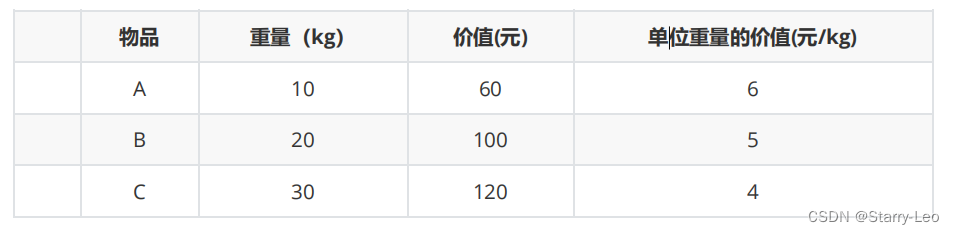
算法(十一)贪婪算法 2024-05-31 算法 17人 已看 贪婪算法(Greedy)是一种在每一步都采取当前状态下最好的或者最优的选择,从而希望导致结果也是全局最好或者最优的算法。贪婪算法是当下局部的最优判断,不能回退。贪婪算法的高效性,以及所求得的答案比较接近最优结果,因此贪心算法可以作为辅助算法或者解决一些要求结果不那么精确的问题。
字节跳动(校招)算法原题 2024-05-24 算法 11人 已看 而在昨天(5 月 22 号)举办的 Baichuan 4 模型产品发布会上,百川智能创始人兼 CEO 王小川也点评了最近的"大模型价格战",其声称:"在中国市场,API 服务其实对创业公司是走不通的"。提到,自从 5 月 15 号,字节跳动发布了击穿行业底价的豆包大模型后,各大厂家纷纷跟进降价,而且都不是普通降价,要么降价 90% 以上,要么直接免费。的所有出边(处理其邻点,将其划分到另一集合上),若在处理过程中发生冲突,则返回。看做无向边的话,可知集合内部无边,即所有的边必然横跨两个集合之间。
数据结构的快速排序(c语言版) 2024-05-31 算法, java, c语言, 数据结构, 开发语言 103人 已看 快速排序是一种常用的排序算法,它是基于分治策略的一种高效排序算法。2.快排的适用场景大规模数据排序:快速排序的平均时间复杂度为O(nlogn),在处理大规模数据时比其他算法如冒泡排序、插入排序更加高效。内存受限的环境:快速排序是一种就地排序算法,不需要额外的存储空间,这在内存受限的环境(如嵌入式系统)中更有优势。数据较为随机分布:快速排序的性能最佳情况发生在数据较为随机分布的情况下。如果数据已经基本有序或完全逆序,则会退化为O(n^2)的时间复杂度。
算法(十一)贪婪算法 2024-05-31 算法 12人 已看 贪婪算法(Greedy)是一种在每一步都采取当前状态下最好的或者最优的选择,从而希望导致结果也是全局最好或者最优的算法。贪婪算法是当下局部的最优判断,不能回退。贪婪算法的高效性,以及所求得的答案比较接近最优结果,因此贪心算法可以作为辅助算法或者解决一些要求结果不那么精确的问题。
【代码随想录算法训练营第37期 第二十五天 | LeetCode216.组合总和III、17.电话号码的字母组合】 2024-05-31 算法, leetcode, 职场和发展 112人 已看 【代码】【代码随想录算法训练营第37期 第二十五天 | LeetCode216.组合总和III、17.电话号码的字母组合】
栈与队列练习题(2024/5/31) 2024-05-31 算法, leetcode, 职场和发展 105人 已看 例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。我们在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
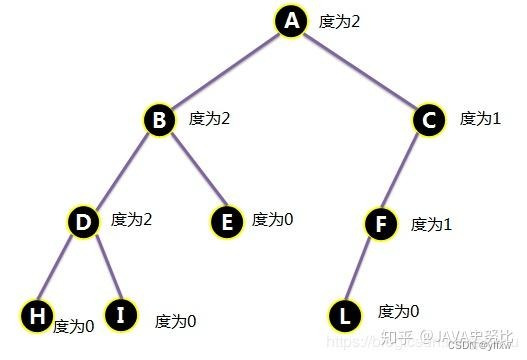
【数据结构】详解二叉树 2024-05-31 算法, 数据结构 66人 已看 在这个方法中,我们用firstchild指针找当前节点的第一个孩子节点(A),再用pnextbrother指针找到后续的孩子节点(B,C)找完之后接着用firstchild找到D,然后重复上面的操作,直到找完为止;对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。:若一个结点含有子结点,则这个结点称为其子结点的父结点;:以某结点为根的子树中任一结点都称为该结点的子孙。:一个结点含有的子树的根结点称为该结点的子结点;
数据结构的快速排序(c语言版) 2024-05-31 算法, java, c语言, 数据结构, 开发语言 100人 已看 快速排序是一种常用的排序算法,它是基于分治策略的一种高效排序算法。2.快排的适用场景大规模数据排序:快速排序的平均时间复杂度为O(nlogn),在处理大规模数据时比其他算法如冒泡排序、插入排序更加高效。内存受限的环境:快速排序是一种就地排序算法,不需要额外的存储空间,这在内存受限的环境(如嵌入式系统)中更有优势。数据较为随机分布:快速排序的性能最佳情况发生在数据较为随机分布的情况下。如果数据已经基本有序或完全逆序,则会退化为O(n^2)的时间复杂度。