计算机毕业设计Python深度学习游戏推荐系统 Django PySpark游戏可视化 游戏数据分析 游戏爬虫 Scrapy 机器学习 人工智能 大数据毕设 2024-07-18 爬虫, 数据分析, django, 机器学习, spark, 人工智能, 游戏, scrapy, 大数据, 课程设计 835人 已看 计算机毕业设计Python深度学习游戏推荐系统 Django PySpark游戏可视化 游戏数据分析 游戏爬虫 Scrapy 机器学习 人工智能 大数据毕设
海外营销推广:快速创建维基百科(wiki)词条-大舍传媒 2024-07-17 传媒, 大数据 488人 已看 三、迅速创建维基百科词条的办法大舍传媒提供优质的维基百科创建服务项目,我们团队了解维基百科的编辑制度和方法,能够迅速、清晰地创建词条。通过维基百科,企业可以提高自身品牌的国际知名度,扩大品牌影响力,同时还可以有效提升企业的搜索引擎排名,从而获得更多的潜在客户。二、创建维基百科的语言挑选创建维基百科时,可供选择的语言比较丰富,包括英语、西语、法文、法语、葡语、波兰语、德语、意大利文和中文等。创建维基百科时,可以选择的语种非常丰富,包括英语、西班牙语、法语、德语、葡萄牙语、波兰语、俄语、意大利语和中文等。
ES索引模板 2024-07-10 elasticsearch, 全文检索, 搜索引擎, 大数据 231人 已看 当你创建了一个索引模板,它会包含一系列的默认设置和映射规则,这些规则会在满足一定条件的新索引被创建时自动应用。总结来说,索引模板是一种策略,它允许你预设一组设置和映射,以便在创建符合特定命名模式的新索引时自动应用这些预设。但是,需要注意的是,如果在创建索引时显式指定了某些设置或映射,那么这些显式指定的值将优先于模板中的值。此外,一旦索引已经被创建,索引模板的更改将不会影响到已经存在的索引。的索引时,该模板将会被应用,从而自动配置索引的设置和映射。,那么当你尝试创建一个确切名称为。开头的索引都会应用该模板。
Elasticsearch:Painless scripting 语言(一) 2024-06-30 elasticsearch, jenkins, 全文检索, 搜索引擎, 大数据 267人 已看 Painless 是一种高性能、安全的脚本语言,专为 Elasticsearch 设计。你可以使用 Painless 在 Elasticsearch 支持脚本的任何地方安全地编写内联和存储脚本。
摸鱼大数据——Spark基础——Spark On Yarn环境配置和部署 2024-07-02 spark, servlet, yarn, 分布式, ajax, 大数据 313人 已看 export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py。/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py。/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py。相比原理hadoop集群,需要多启动一个spark的自己的历史服务,它是依赖hadoop的历史服务的!
ES|使用Postman更新ES内所有文档的指定字段 2024-07-01 elasticsearch, postman, jenkins, lua, 大数据 210人 已看 在日常的数据管理任务中,有时我们需要批量更新Elasticsearch中大量文档的某一字段,以反映最新的业务需求或数据修正。本文将学习如何使用Postman结合Elasticsearch的`Update By Query` API来高效完成这项工作。
数据中台高频面试题及参考答案(持续更新) 2024-06-27 spark, 分布式, 大数据 335人 已看 数据脱敏,又称为数据屏蔽或数据混淆,是一种信息安全技术,旨在保护敏感信息和隐私数据免受未经授权的访问或泄露。它通过在保留数据格式和结构的同时,对原始数据中的敏感部分进行有策略的修改或替换,生成一个看似真实但不含实际敏感细节的数据副本。这样处理后的数据可以在非生产环境,如开发、测试、分析或培训等场景中安全使用,既保证了数据的可用性,又维护了数据主体的隐私安全。数据脱敏的方法多样,包括替换、掩码、哈希、随机化、扰码等,可根据不同数据类型的特性和安全要求选择合适的脱敏策略。
Spark性能优化(第22天) 2024-07-01 spark, 性能优化, 分布式, 大数据 293人 已看 Spark性能优化是一个系统工程,涉及多个方面,包括开发调优、资源调优、数据倾斜调优、shuffle调优等。在Spark作业的执行过程中,任何一个环节的不足都可能导致性能瓶颈。因此,我们需要从多个角度出发,对Spark作业进行全面的优化。
零点到两点,我部署了一个es 2024-06-27 elasticsearch, jenkins, 全文检索, 搜索引擎, 大数据 187人 已看 实在是水平有限,Clash虚拟机网出不去,研究了LAN方案,还在咸鱼买了一单,搞不定,没辙,那我老老实实下载tar包得了,就不docker了。
Elasticsearch 第四期:搜索和过滤 2024-06-30 elasticsearch, 全文检索, 搜索引擎, 大数据 196人 已看 本文先介绍了相关性的知识,然后从全文搜 索,词项搜索,复合搜索三方面来介绍了ES搜索的常见场景和操作。最后介绍了与搜索对应的过滤操作。本文的内容意在梳理ES搜索操作,并未细究背后的原理,如相关性算法等。后续如果有需要会补充。当然,在实际应用中,要综合考虑具体场景来选择相应的搜索方式。参考文档Elasticsearch 7.x文档检索的三大策略:全文搜索、词项搜索与复合搜索-百度开发者中心。
Spark join数据倾斜调优 2024-06-30 spark, ajax, 分布式, 大数据, javascript 262人 已看 一般情况下是某个task处理的数据量远大于其他task处理的数据量,当然也不排除是程序代码没有冗余,异常数据导致程序运行异常。常见的退出码143、53、137、52以及heartbeat timed out异常,通常可认为是executor内存被打满。
ES报错:解决too_many_clauses: maxClauseCount is set to 1024 报错问题 2024-06-27 elasticsearch, 全文检索, 搜索引擎, 大数据 184人 已看 以及其他的查询生成的子句数量超过了Elasticsearch的默认限制(尝试减少子句数量,优化子句的查询数量,使得能减少到1024的个数限制。如果确实需要大量的子句,可以增加Elasticsearch中的。如果前两种方法不可行,考虑使用性能更好的查询类型,比如。查询精确,但它性能更好,并且不会产生过多的子句。查询语句:查询clcNo分类号包含分类。可能扩展为大量词条的查询中超过了限制。我这里的错误是由于使用。这里是一个优化后的查询示例,将。从报错信息来看,查询出现了。错误,这是因为使用的。
大模型+多模态合规分析平台,筑牢金融服务安全屏障 2024-06-26 安全, 人工智能, 物联网, 大数据 159人 已看 依托大量技术应用实践,中关村科金推出以用户为中心的“三位一体”消保管理体系,通过事前预防、事中监督、事后考核,全链路、全流程建设消保体制。
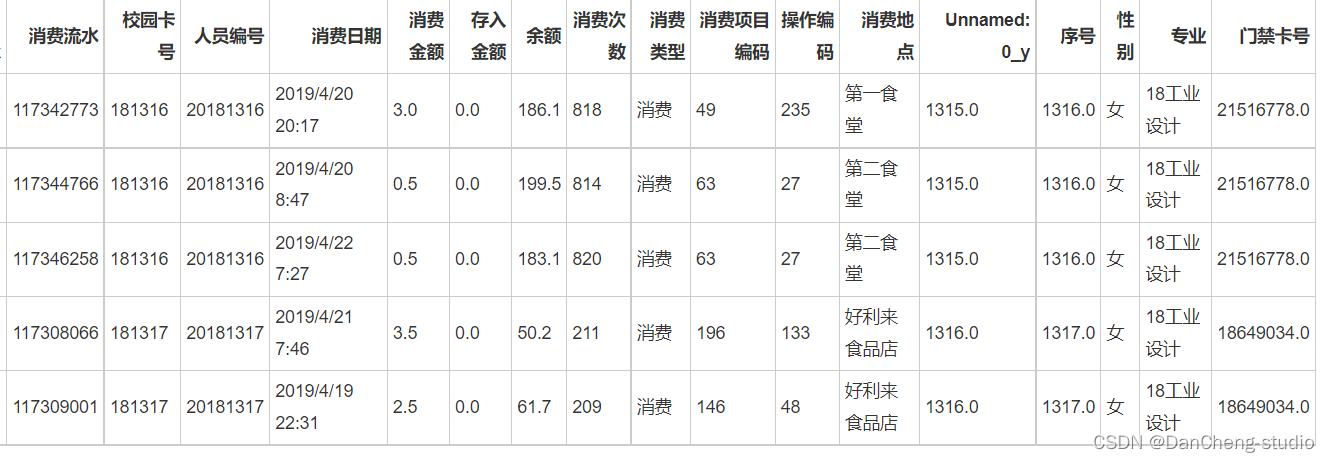
竞赛选题 python+大数据校园卡数据分析 2024-06-25 python, 数据分析, 大数据, 数据挖掘, 开发语言 190人 已看 近年来,大数据的受关注程度越来越高。如何对大数据流进行抽取转换成有用的信息并应用于各行各业变得越来越重要。如今,校园一卡通系统在高校应用十分广泛,大部分高校主要利用校园一卡通对校园中的各类消费阅、补助领取等进行统一管理。通过数据分析算法,对大学生校内消费记录进行整理、分类、预测,从而整体反应学生在校消费情况,形成量化的评判标准,同时也为今后的贫困生资助管理工作提供可靠的数据支持,辅助完成贫困生的相关工作。🧿。
HBase与Hive数据交互 2024-06-28 hive, 数据库, 分布式, 大数据, hbase 257人 已看 其中t_gdp是原始数据表,tmp_gdp_table是和hbase中gdp表关联的外部表,将t_gdp表中的数据insert到了tmp_gdp_table表中,正常的业务中,可能是查询了多个表,通过sql处理将数据存到tmp_gdp_table中,然后通过外部表映射的方式同步到habse的gdp表中。hive外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。两种方式加载hbase中的表到hive中,一是hive创建外部表关联hbase表数据,是hive创建普通表将hbase的数据加载到本地。
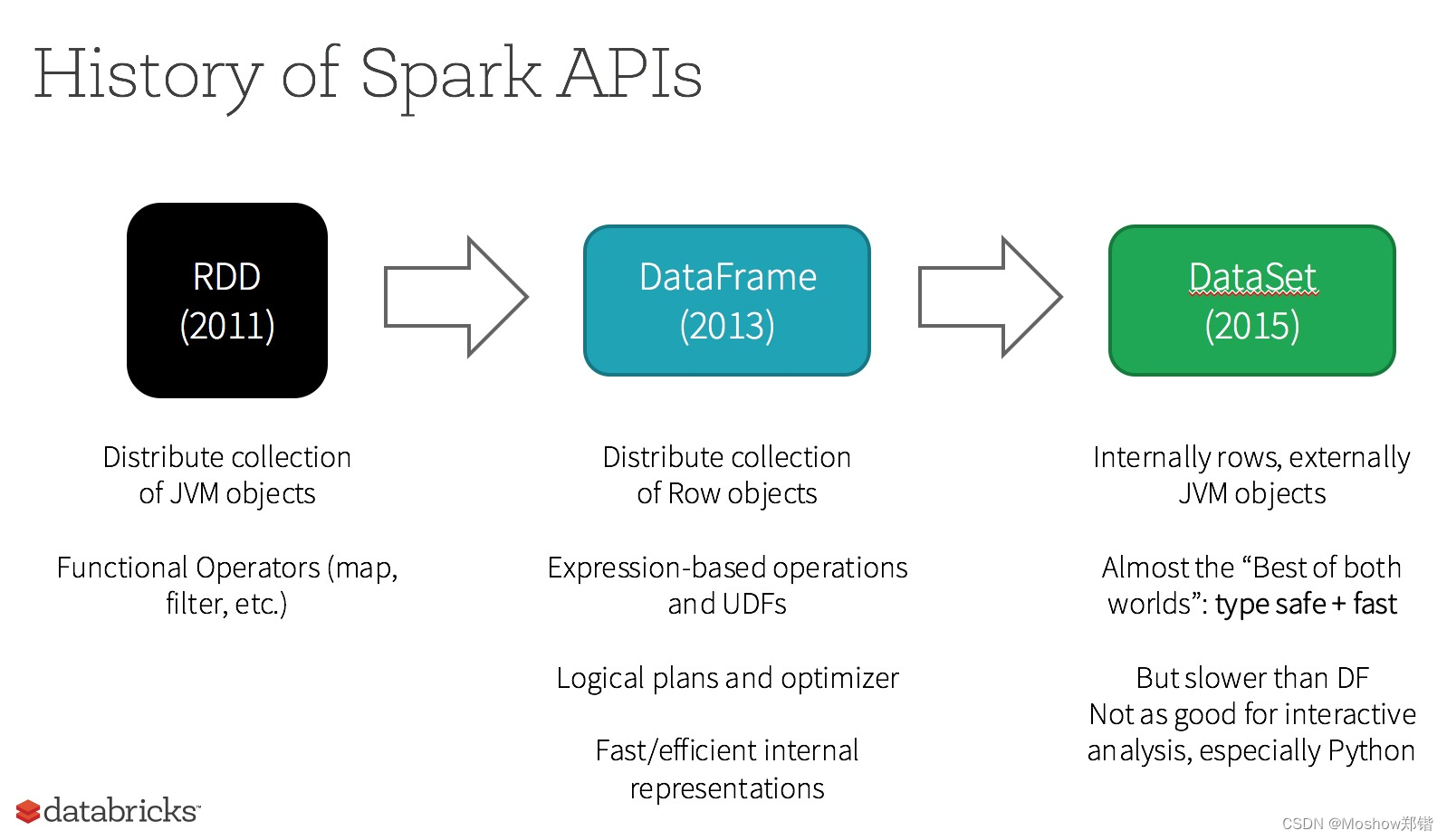
SpringBoot使用Spark的DataFrame API 2024-06-30 spring, java, spark, 后端, 大数据 146人 已看 Apache Spark是一个开源的分布式计算系统,它提供了一个快速和通用的集群计算平台。Spark 能够处理大规模数据,支持多种编程语言,如Scala、Java和Python,并且具有多种高级功能,包括SQL查询、机器学习、图处理和实时数据流处理。Spark是一个功能强大且灵活的计算平台,适用于各种大数据处理场景。通过其丰富的API和组件,Spark能够满足从批处理到实时处理、从数据处理到机器学习的多种需求。
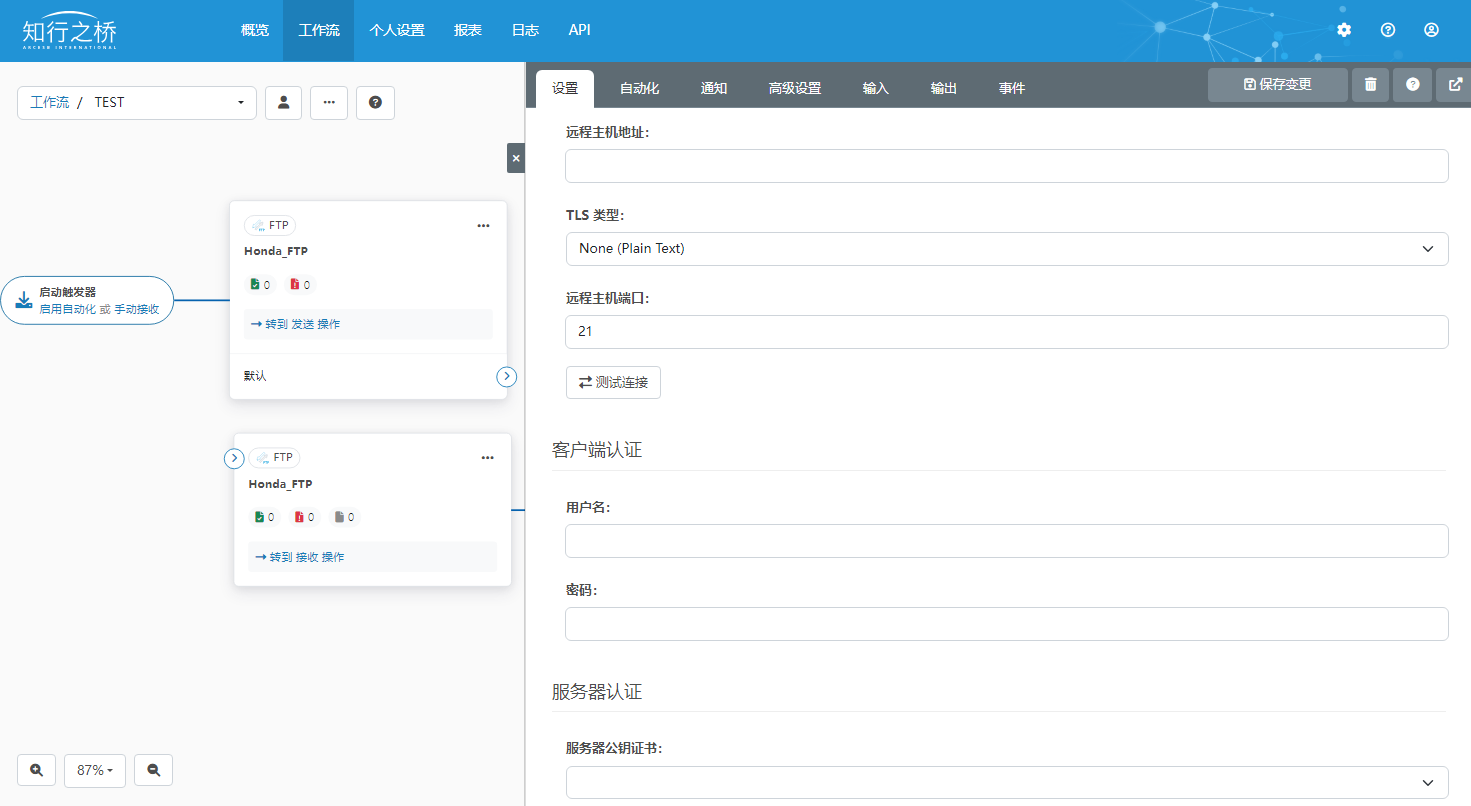
如何与Honda建立EDI连接? 2024-06-28 网络, 大数据 141人 已看 你是的新供应商,需要具备EDI电子数据交换功能吗?在与本田Honda交换EDI消息时需要帮助吗?本文将带你快速了解Honda的EDI需求,明确EDI对接需要完成的工作。
C++标准模板(STL)- 迭代器库 - 流迭代器- 写入 std::basic_ostream 的输出迭代器(二) 2024-06-29 c++, 数据库, 大数据, 开发语言 132人 已看 插入 value 到关联的流,然后插入分隔符,若在构造时指定它。不做任何事,提供此函数以满足遗留输出迭代器 (LegacyOutputIterator) 的要求。不做任何事。提供这些运算符以满足遗留输出迭代器 (LegacyOutputIterator) 的要求。它们使得表达式 *iter++=value 和 *++iter=value 可用于输出(插入)值到底层的流。
Hadoop 面试题(十) 2024-06-25 算法, 深度优先, hadoop, 分布式, 大数据 161人 已看 1. 简述下列关于Hadoop命令中,命令执行成功返回0,执行失败返回-1,下列命令返回-1的是 ?2. 关于DataNode描述中,不正确的是 ?3. 简述关于Hadoop常用命令中,touchz和Linux系统的touch命令的描述正确的是 ?4. 简述Hadoop和Hadoop生态圈的描述中,正确的是 ?5. 简述关于安全模式的描述错误的是() ?6. 简述有关Hadoop系统小文件问题的描述错误的是 ?