探索AI视频生成技术的原理 2024-06-13 机器学习, 计算机视觉, 音视频, 深度学习, 人工智能 210人 已看 AI视频生成技术利用人工智能算法,自动生成视频内容。这些算法通过学习大量的视频数据,能够理解和模拟视频中的视觉和声音元素,从而生成高度逼真的视频内容。AI视频生成技术的核心包括生成对抗网络(GANs)、自回归模型和变分自编码器(VAEs)等。AI视频生成技术正在改变我们制作和消费视频内容的方式。通过深入理解其原理,并不断探索其应用,我们可以更好地利用这一技术,创造出更加丰富和多样的内容。希望这篇文章能为你提供一些启发和帮助,助你在AI视频生成领域取得更多的突破。
python 如何生成原创文章 2024-06-16 python, 深度学习, 人工智能, 开发语言 151人 已看 然而,这些模型生成的文本可能并不总是完全原创,因为它们可能会受到训练数据中的模式和偏见的影响。例如,程序可以询问用户关于文章的标题、主题、段落数量等问题,然后根据用户的回答来生成一个文章框架,用户可以在此基础上进行进一步的编辑和扩展。例如,你可以有一个新闻文章的模板,其中包含了标题、日期、作者、正文等部分,然后使用Python来动态地生成这些部分的内容。如果你有一个关于特定主题的知识库,你可以使用Python来从这个知识库中提取信息,并生成关于该主题的文章。有一些Python库,如。
【机器学习】人工智能与气候变化:利用深度学习与机器学习算法预测和缓解环境影响 2024-06-16 机器学习, 深度学习, 人工智能 160人 已看 全球气候变化已成为世界各国共同面对的重大挑战之一。气候变化带来的极端天气事件频发、海平面上升、生态系统退化等问题,严重影响着人类的生存和发展。因此,寻找有效的方法来预测气候变化趋势并采取相应的应对措施至关重要。
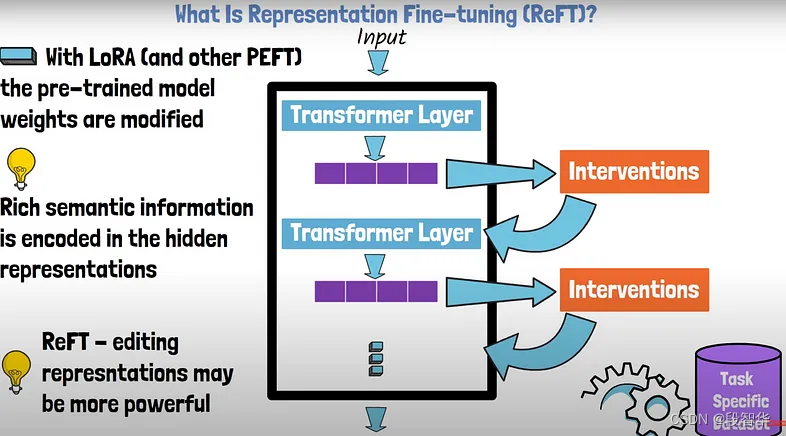
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预 2024-06-09 llama, 机器学习, 深度学习, 人工智能, 自然语言处理 252人 已看 代码定义了多个类和函数,用于处理自然语言处理(NLP)任务中的干预(intervention)机制
基于深度学习的电池健康状态预测(Python) 2024-06-12 python, 深度学习, 人工智能, 开发语言 129人 已看 电池的故障预测和健康管理PHM是为了保障设备或系统的稳定运行,提供参考的电池健康管理信息,从而提醒决策者及时更换电源设备。不难发现,PHM的核心问题就是确定电池的健康状态,并预测电池剩余使用寿命。但是锂电池的退化过程影响因素众多,不仅受其本身工作模式的影响,外部环境的压力、温度等都会影响锂电池的退化。这些影响因素之间的相互耦合,导致锂电池的退化表现出很强的非线性及不确定性,这给SOH估计和RUL预测带来了很大的困难。
【AI原理解析】— Meta Llama-3模型 2024-06-13 llama, 机器学习, 深度学习, 人工智能 231人 已看 Meta Llama3通过优化的Transformer架构、大规模参数、扩展的训练数据集、先进的训练方法、增强的安全性和多语言支持等原理,成为了一个功能强大、性能卓越的开源大型语言模型。
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集 2024-06-08 llama, 算法, 机器学习, 深度学习, 人工智能 239人 已看 为 ReFT 微调准备模型及数据集 。为微调准备数据集。 使用了OpenHermes-2.5数据集的1万条子集。由于REFT训练器期望数据以特定格式提供, 将使用pyreft.make_last_position_supervised_data_module()来准备数据。
从零实现ChatGPT:第一章构建大规模语言模型的数据准备 2024-06-08 语言模型, 机器学习, 深度学习, 人工智能, chatgpt 234人 已看 LLM需要将文本数据转换为数值向量,称为嵌入,因为它们无法处理原始文本。嵌入将离散数据(如单词或图像)转换为连续向量空间,使其与神经网络运算兼容。作为第一步,原始文本被分解为标记,可以是单词或字符。然后,标记被转换为称为标记ID的整数表示。可以添加特殊标记,如_unk_>和_endoftext_>,以增强模型的理解并处理各种上下文,例如未知单词或标记不相关文本之间的边界。GPT和GPT-2等LLM使用的字节对编码(BPE)标记化器可以通过将未知单词分解为子词单元或单个字符来有效处理未知单词。
Pytorch--Hooks For Module 2024-06-11 python, 机器学习, 深度学习, pytorch, 人工智能 158人 已看 在 PyTorch 中,register_module_forward_hook 是一个方法,用于向模型的模块注册前向传播钩子(forward hook)。在 PyTorch 中,register_module_backward_hook 是一个方法,用于向模型的模块注册反向传播钩子(backward hook)。在 PyTorch 中,register_module_forward_pre_hook 是一个方法,用于向模型的模块注册前向传播预钩子(forward pre-hook)。
计算机毕业设计Python+Spark知识图谱酒店推荐系统 酒店评论情感分析 酒店价格预测系统 酒店可视化 酒店爬虫 neo4j知识图谱 深度学习 2024-06-12 爬虫, python, neo4j, spark, 深度学习, 知识图谱 299人 已看 计算机毕业设计Python+Spark知识图谱酒店推荐系统 酒店评论情感分析 酒店价格预测系统 酒店可视化 酒店爬虫 neo4j知识图谱 深度学习
【2024算力大会分会 | SPIE独立出版 | 往届均已完成EI检索】2024云计算、性能计算与深度学习国际学术会议(CCPCDL 2024) 2024-06-11 深度学习, 人工智能, 云计算 234人 已看 2024云计算、性能计算与深度学习国际学术会议(CCPCDL 2024)将于2024年8月14-16日在中国郑州举行。CCPCDL已成功召开两届,并且均已实现EI核心和Scopus检索,第三届将作为2024算力大会分会,聚焦云计算、性能计算、深度学习等前沿研究领域。会议所有录用文章在完成注册后被SPIE 独立出版,并被EI Compendex 和 Scopus 检索。高质量论文将遴选至2024算力大会,由IEEE出版,见刊后提交至 EI Compendex和Scopus检索。往届最快会后4个月实现EI检索
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预 2024-06-09 llama, 机器学习, 深度学习, 人工智能, 自然语言处理 257人 已看 代码定义了多个类和函数,用于处理自然语言处理(NLP)任务中的干预(intervention)机制
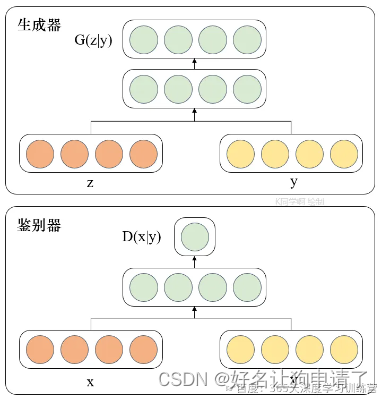
G5 - Pix2Pix理论与实战 2024-06-07 机器学习, 计算机视觉, 深度学习, 人工智能 151人 已看 通过对Pix2Pix模型的学习,最让我印象深刻的特点是它把判别器由CGAN那种统一压缩完直接预测的逻辑转换成了分成一个Patch,这样提升了模型生成的精度。在了解了这个修改后,我对之前GAN和CGAN产生的斑点很多的生成有了更加深入的理解。应该是由于模型对特征的压缩,导致部分像素失去代表性,产生斑点。还有一个印象深刻的点是完全随机的噪声zzz。
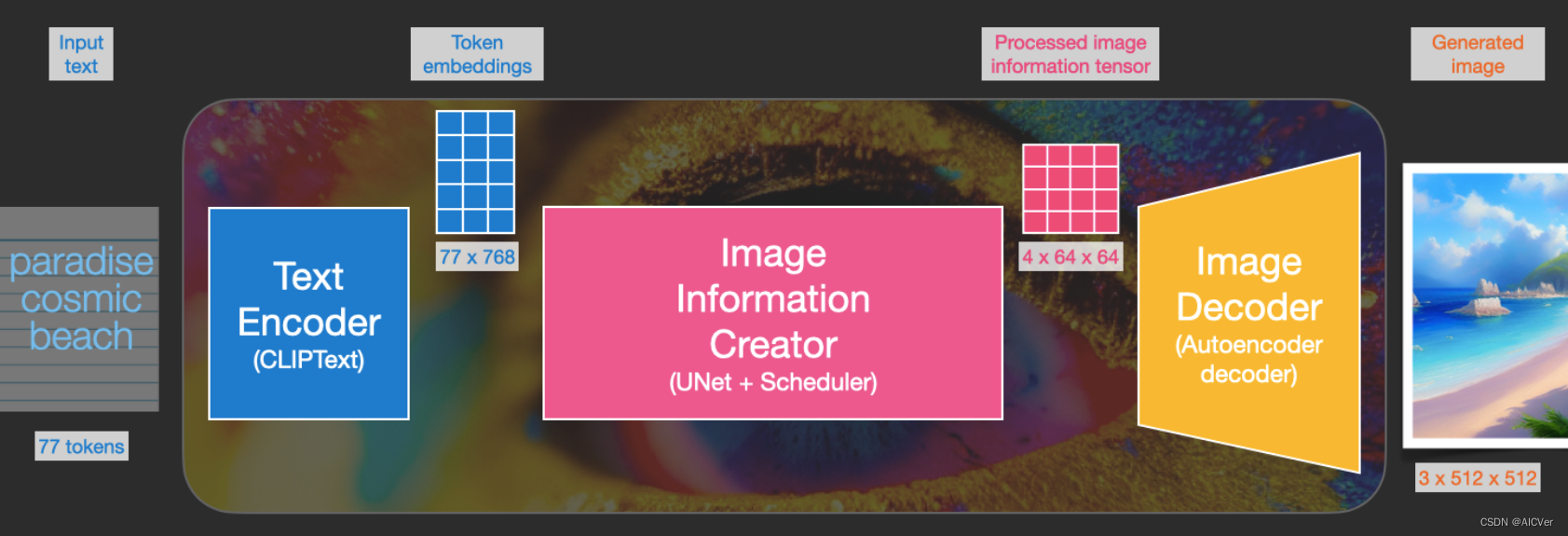
扩散模型Stable Diffusion 2024-06-09 机器学习, stable diffusion, 深度学习, 人工智能 162人 已看 Clip Text为文本编码器。以77 token为输入,输出为77 token 嵌入向量,每个向量有768维度。
第P10周:Pytorch实现车牌识别 2024-06-13 python, 机器学习, 深度学习, pytorch, 人工智能 159人 已看 在之前的案例中,我们多是使用datasets.ImageFolder函数直接导入已经分类好的数据集形成Dataset,然后使用DataLoader加载Dataset,但是如果对无法分类的数据集,我们如何导入,并进行识别呢?本周我将自定义一个MyDataset加载车牌数据集并完成车牌识别。
基于CNN-RNN模型的验证码图片识别 2024-06-13 cnn, rnn, 深度学习, 人工智能, 神经网络 300人 已看 基于CNN-RNN模型的验证码识别方法能够有效处理复杂的验证码问题,结合了卷积神经网络的特征提取能力和循环神经网络的序列建模能力。通过使用CTC解码,可以在没有逐帧标注的情况下预测验证码中的字符序列。这种方法在实际应用中具有很高的准确率和适应性。
[深度学习]基于C++和onnxruntime部署yolov10的onnx模型 2024-06-13 yolo, c++, 深度学习, 人工智能, 开发语言 177人 已看 使用C#部署yolov8的目标检测tensorrt模型,C# winform部署yolov10的onnx模型,YOLOv8检测界面-PyQt5实现,2024年新版【YOLOV5从入门到实战教程】B站最良心的YOLOV5全套教程(适合小白)含源码!:解析模型输出的结果,这通常涉及将输出的张量数据转换为可理解的检测结果,如边界框坐标和类别标签。:通过ONNX Runtime的推理引擎,将图像数据输入到模型中,并执行目标检测任务。:使用ONNX Runtime的API加载转换后的YOLOv10 ONNX模型。
torch.squeeze() dim=1 dim=-1 dim=2 2024-06-12 python, 机器学习, 深度学习, 人工智能, pytorch 172人 已看 对数据的维度进行压缩将输入张量形状中的1 去除并返回。如果输入是形如(A×1×B×1×C×1×D),那么输出形状就为: (A×B×C×D)当给定dim时,那么挤压操作只在给定维度上。例如,输入形状为: (A×1×B), squeeze(input, 0) 将会保持张量不变,只有用 squeeze(input, 1),形状会变成 (A×B)。
一步一步用numpy实现神经网络各种层 2024-06-13 机器学习, 深度学习, 人工智能, numpy, 神经网络 186人 已看 单独求softmax层有点麻烦, 将softmax+entropy一起求导更方便。为ground truth, 为one-hot vector.