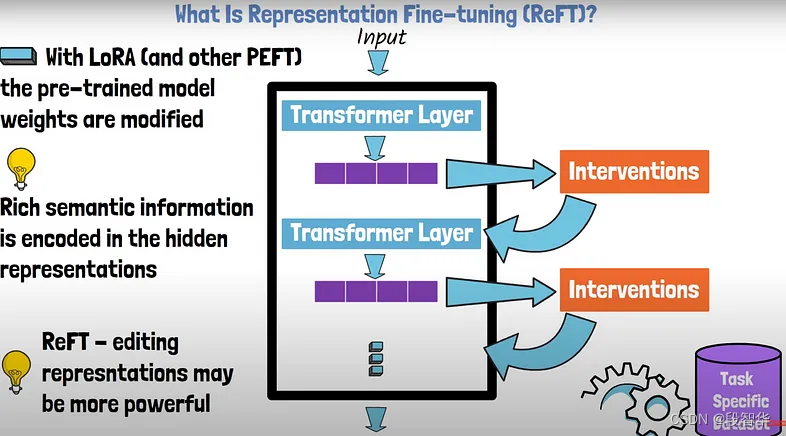
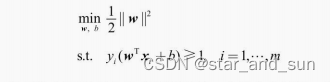Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预 2024-06-09 llama, 机器学习, 深度学习, 人工智能, 自然语言处理 48人 已看 代码定义了多个类和函数,用于处理自然语言处理(NLP)任务中的干预(intervention)机制
生成式人工智能 - stable diffusion web-ui安装教程 2024-06-07 笔记, ui, 机器学习, stable diffusion, 人工智能, 前端 38人 已看 屌丝劲发作了,所以本地调试了Stable Diffusion之后,就去看了一下Stable Diffusion WEB UI,网络上各种打包套件什么的好像很火,但实际上确实也没多麻烦,我们这里从大神的git源码直接开始。下载源码肯定是第一步的。直接运行Stable Diffusion的源码和预训练模型可以参考下面的链接。机器学习笔记 - 本地windows 11 + PyCharm运行stable diffusion流程简述-CSDN博客文章浏览阅读46次。
生成式人工智能 - 本地windows 11 + PyCharm运行stable diffusion流程简述 2024-06-06 python, 笔记, 机器学习, stable diffusion, pycharm, 人工智能, ide 39人 已看 硬件:本地电脑windows11、32.0 GB内存、2060的6G的卡。软件:本地有一个python环境,主要是torch 2.2.2+cu118。
【AI原理解析】— Meta Llama-3模型 2024-06-13 llama, 机器学习, 深度学习, 人工智能 47人 已看 Meta Llama3通过优化的Transformer架构、大规模参数、扩展的训练数据集、先进的训练方法、增强的安全性和多语言支持等原理,成为了一个功能强大、性能卓越的开源大型语言模型。
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集 2024-06-08 llama, 算法, 机器学习, 深度学习, 人工智能 43人 已看 为 ReFT 微调准备模型及数据集 。为微调准备数据集。 使用了OpenHermes-2.5数据集的1万条子集。由于REFT训练器期望数据以特定格式提供, 将使用pyreft.make_last_position_supervised_data_module()来准备数据。
从零实现ChatGPT:第一章构建大规模语言模型的数据准备 2024-06-08 语言模型, 机器学习, 深度学习, 人工智能, chatgpt 46人 已看 LLM需要将文本数据转换为数值向量,称为嵌入,因为它们无法处理原始文本。嵌入将离散数据(如单词或图像)转换为连续向量空间,使其与神经网络运算兼容。作为第一步,原始文本被分解为标记,可以是单词或字符。然后,标记被转换为称为标记ID的整数表示。可以添加特殊标记,如_unk_>和_endoftext_>,以增强模型的理解并处理各种上下文,例如未知单词或标记不相关文本之间的边界。GPT和GPT-2等LLM使用的字节对编码(BPE)标记化器可以通过将未知单词分解为子词单元或单个字符来有效处理未知单词。
Pytorch--Hooks For Module 2024-06-11 python, 机器学习, 深度学习, pytorch, 人工智能 33人 已看 在 PyTorch 中,register_module_forward_hook 是一个方法,用于向模型的模块注册前向传播钩子(forward hook)。在 PyTorch 中,register_module_backward_hook 是一个方法,用于向模型的模块注册反向传播钩子(backward hook)。在 PyTorch 中,register_module_forward_pre_hook 是一个方法,用于向模型的模块注册前向传播预钩子(forward pre-hook)。
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预 2024-06-09 llama, 机器学习, 深度学习, 人工智能, 自然语言处理 53人 已看 代码定义了多个类和函数,用于处理自然语言处理(NLP)任务中的干预(intervention)机制
人工智能和机器学习这两个概念有什么区别? 2024-06-10 机器学习, 人工智能 32人 已看 机器学习,MachineLearning(简称ML),机器学习领域知名学者Tom M.Mitchell曾给机器学习做如下定义:如果计算机程序针对某类任务T的性能(用P来衡量)能通过经验E来自我改善,则认为关于T和P,程序对E进行了学习。通俗来讲,计算机针对某一任务,从经验中学习,并且能越做越好,这一过程就是机器学习。一般情况下,“经验”都是以数据的方式存在的,计算机程序从这些数据中学习。学习的关键是模型算法,它可以学习已有的经验数据,用以预测未知数据。
【线性代数】向量空间,子空间,向量空间的基和维数 2024-06-09 算法, python, 机器学习, 线性代数, 开发语言 46人 已看 设V为n维向量的集合,如果V非空,且集合V对于向量的加法以及数乘两种运算封闭,那么就称集合V为向量空间x,y是n维列向量。x向量组等价说明可以互相线性表示向量组等价则生成的向量空间是一样的。
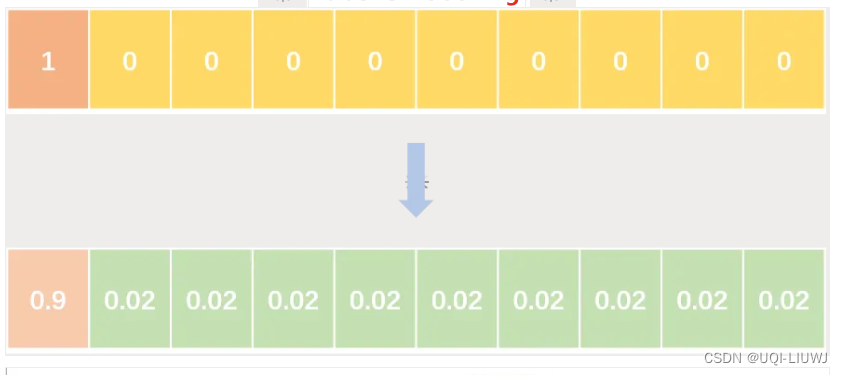
机器学习笔记:label smoothing 2024-06-10 笔记, 机器学习, 人工智能 35人 已看 在传统的分类任务中,我们通常使用硬标签(hard labels) 即如果一个样本属于某个类别,其对应的标签就是一个全0的向量,除了表示这个类别的位置为1。 例如,在一个3类分类任务中,某个样本的标签可能是 [0,1,0] Label Smoothing 的思想是将这些硬标签替换为软标签(soft labels)。 例如,对于上述的三类问题,我们可以将标签 [0,1,0]转换为 [0.1,0.8,0.1] 这样做的效果是降低模型对于标签的绝对信任度,鼓励模型学习到更加平滑的概率分布
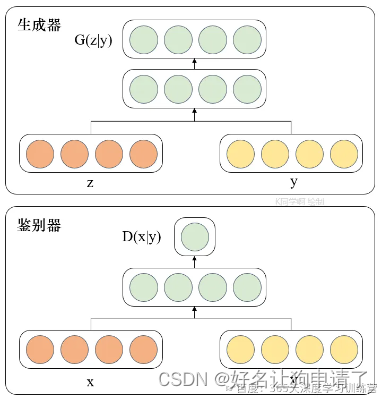
G5 - Pix2Pix理论与实战 2024-06-07 机器学习, 计算机视觉, 深度学习, 人工智能 36人 已看 通过对Pix2Pix模型的学习,最让我印象深刻的特点是它把判别器由CGAN那种统一压缩完直接预测的逻辑转换成了分成一个Patch,这样提升了模型生成的精度。在了解了这个修改后,我对之前GAN和CGAN产生的斑点很多的生成有了更加深入的理解。应该是由于模型对特征的压缩,导致部分像素失去代表性,产生斑点。还有一个印象深刻的点是完全随机的噪声zzz。
机器学习笔记——支持向量机 2024-06-10 算法, 支持向量机, 笔记, 机器学习, 人工智能 43人 已看 思想:同时优化所有的参数比较困难,因此选择部分参数来优化,选择两个固定其他的,然后再选两个固定其他的一直循环,直到更新参数的变化小于某个值就可以终止,或者固定迭代次数。我们只需要用支持向量来进行分类,这样子减少了复杂度和时间消耗,但是优势不明显,因为参数a的求解需要的时间也很大,所以用到了序列最小优化算法来解决这个问题。对于一个样本,要么对应的参数a为0,要么与超平面的间隔为γ,将这些与超平面距离最小的向量。这里的a是待求解的参数,梯度参数量是和规模m相关,数据的规模增大时,参数量也增多。
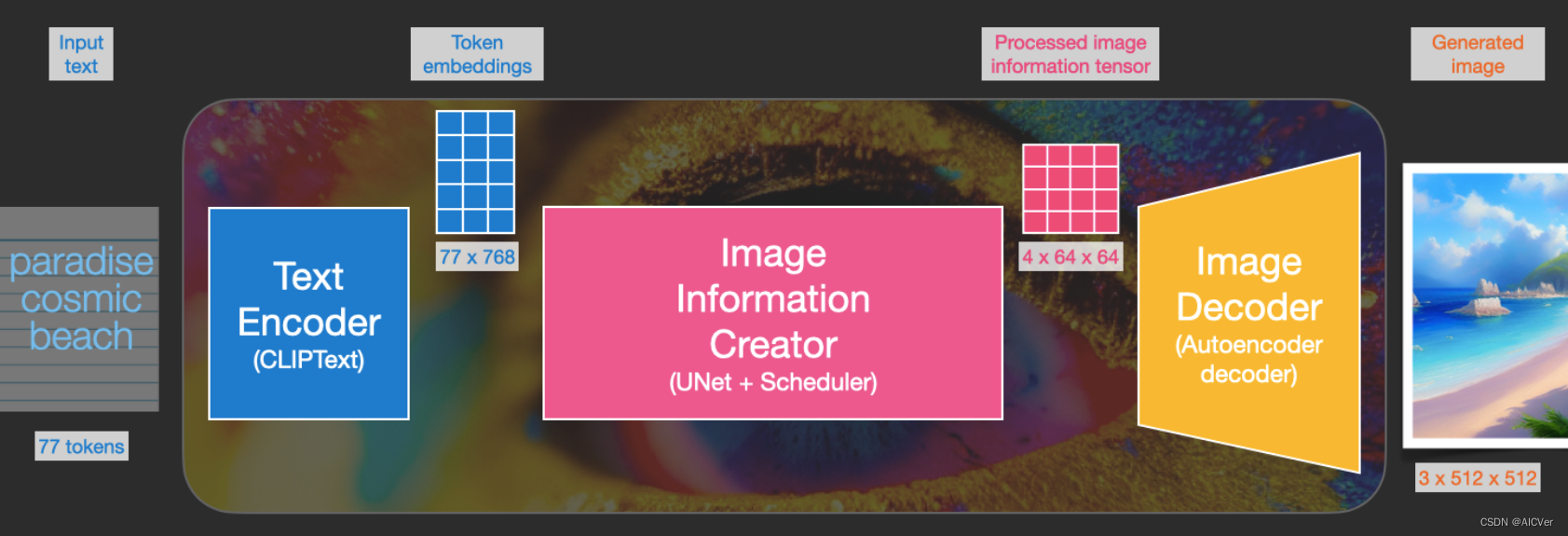
扩散模型Stable Diffusion 2024-06-09 机器学习, stable diffusion, 深度学习, 人工智能 34人 已看 Clip Text为文本编码器。以77 token为输入,输出为77 token 嵌入向量,每个向量有768维度。
机器学习--线性模型和非线性模型的区别?哪些模型是线性模型,哪些模型是非线性模型? 2024-06-09 机器学习, 人工智能 45人 已看 优点:简单、易解释、训练速度快、计算效率高。缺点:无法处理复杂的非线性关系,对数据分布要求高。适用场景:输入特征和输出变量之间存在明显线性关系,数据量大且结构较简单。
第P10周:Pytorch实现车牌识别 2024-06-13 python, 机器学习, 深度学习, pytorch, 人工智能 40人 已看 在之前的案例中,我们多是使用datasets.ImageFolder函数直接导入已经分类好的数据集形成Dataset,然后使用DataLoader加载Dataset,但是如果对无法分类的数据集,我们如何导入,并进行识别呢?本周我将自定义一个MyDataset加载车牌数据集并完成车牌识别。