Python 爬虫编写入门 2024-05-20 爬虫, python, 开发语言 22人 已看 网络爬虫(Web Crawler)或称为网络蜘蛛(Web Spider),是一种按照一定规则,自动抓取互联网信息的程序或者脚本。它们可以自动化地浏览网络中的信息,通过解析网页内容,提取所需的数据,并保存下来供后续分析使用。需要替换为实际要爬取的网页 URL。另外,为了运行上述代码,你需要先安装。这两个 Python 库。
爬虫学习--12.MySQL数据库的基本操作(下) 2024-05-20 学习, 爬虫, 数据库, sql 10人 已看 MySQL查询数据MySQL 数据库使用SQL SELECT语句来查询数据。语法:在MySQL数据库中查询数据通用的 SELECT 语法
TypeScript 爬虫实践:选择最适合你的爬虫工具 2024-05-16 爬虫 13人 已看 今天我们将探讨如何使用 TypeScript 构建网络爬虫。网络爬虫是一种强大的工具,可以帮助我们从互联网上收集数据,进行分析和挖掘。而 TypeScript,则是一种类型安全的 JavaScript 超集,它可以让我们在编写 JavaScript 代码时享受到更严格的类型检查和更好的开发体验。本文将介绍如何选择最适合你的网络爬虫工具,并分享一些实用的案例。
TypeScript 爬虫实践:选择最适合你的爬虫工具 2024-05-16 爬虫 14人 已看 今天我们将探讨如何使用 TypeScript 构建网络爬虫。网络爬虫是一种强大的工具,可以帮助我们从互联网上收集数据,进行分析和挖掘。而 TypeScript,则是一种类型安全的 JavaScript 超集,它可以让我们在编写 JavaScript 代码时享受到更严格的类型检查和更好的开发体验。本文将介绍如何选择最适合你的网络爬虫工具,并分享一些实用的案例。
爬虫学习--12.MySQL数据库的基本操作(下) 2024-05-20 学习, 爬虫, 数据库, sql 12人 已看 MySQL查询数据MySQL 数据库使用SQL SELECT语句来查询数据。语法:在MySQL数据库中查询数据通用的 SELECT 语法
php爬虫之获取淘宝商品数据 2024-05-22 爬虫, php, 开发语言 21人 已看 上图是前三页的url地址,你会发现其实并没有太大的变化,经过测试发现,真正有效的参数是框起来的内容,它的变化会导致页面的跳转,很明显第一页的s=0,第二页s=44,第三页s=88,以此类推,之后就可以轻松做到翻页了。因为之前,在配置Python环境变量的时候,就将Python的目录放到我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path。selenium是一个用于测试网站的自动化测试工具,支持很多主流的浏览器,比如:谷歌浏览器、火狐浏览器、IE、Safari等。
什么是谷歌爬虫? 2024-05-18 爬虫 18人 已看 谷歌爬虫的工作是非常关键的,它决定我们去谷歌搜索相关内容会出现什么,而我们做网站优化,第一时间也是需要吸引爬虫前来,没有爬虫前来的网站,谷歌甚至不知道你的网站存在,其他的优化就再多也是白搭,想做谷歌优化,谷歌爬虫很重要,所以GPC爬虫池的出现可以是网站优化的一大利器,能第一时间让谷歌知道你的网站,收录你的网站。其实就是谷歌用来浏览网络信息的一个自动化程序,他们会在你的网站爬取,寻找和搜集信息,谷歌爬虫可以说决定着一个网站在谷歌的生死。
go 爬虫之 colly 简单示例 2024-05-22 爬虫, golang, 后端, 开发语言 18人 已看 colly 是 Go 实现的比较有名的一款爬虫框架,而且 Go 在高并发和分布式场景的优势也正是爬虫技术所需要的。它的主要特点是轻量、快速,设计非常优雅,并且分布式的支持也非常简单,易于扩展。
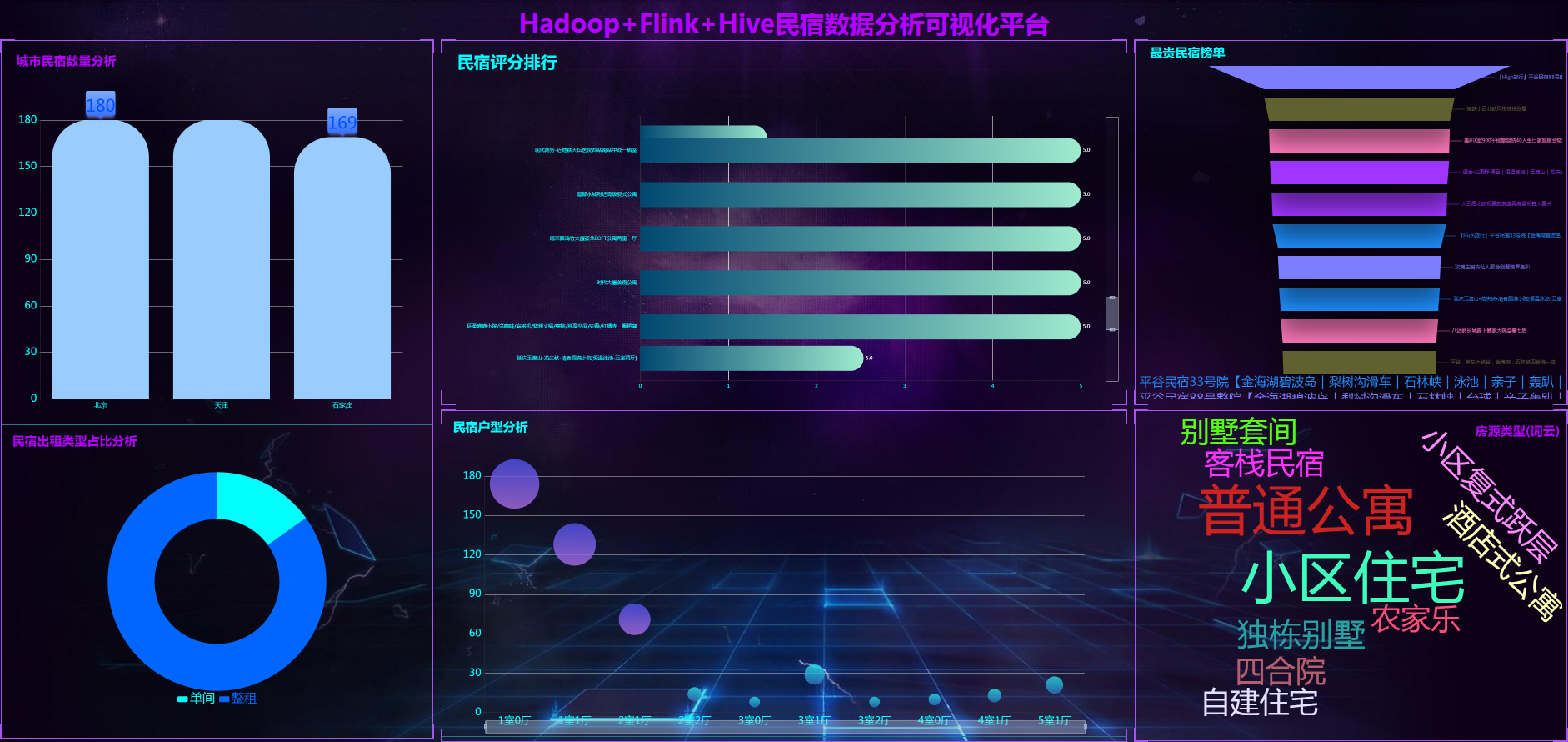
计算机毕业设计PyFlink+Spark+Hive民宿推荐系统 酒店推荐系统 民宿酒店数据分析可视化大屏 民宿爬虫 民宿大数据 知识图谱 机器学习 2024-05-19 hive, flink, 爬虫, 数据分析, 机器学习, spark, 知识图谱, 大数据 52人 已看 计算机毕业设计PyFlink+Spark+Hive民宿推荐系统 酒店推荐系统 民宿酒店数据分析可视化大屏 民宿爬虫 民宿大数据 知识图谱 机器学习
前后端分离项目做爬虫收录,提供蜘蛛爬行最简单方案,创建sitemap xml 2024-05-14 爬虫, xml 12人 已看 那么就可以直接在get的页面的内容接口直接放在地图,让蜘蛛直接获取接口返回的json内容,就不需要渲染,达到让不使用ssr,ssg来让爬虫爬取内容的方法。爬虫是会先爬取 http://127.0.0.1/robots.txt 去读取爬虫规则的,这里面是可以指定stemap xml地址的。很多年前接手一个angularjs的项目,但是要搞爬虫收录,搞了好久那个时候ssr支持的不太好,所以想了另一个方法。会去求证一下百度蜘蛛爬虫是否可行,我们当年是可以的,因为爬虫技术一直在变,最好找官方支持一下。
爬虫部分知识点(1) 2024-05-15 爬虫, python, 开发语言 13人 已看 好了,这篇我就只写这么多,并不是我不想多写,而是爬虫本身的成分复杂,我怕误写一些不该写的,爬虫这部分我也只会写几篇。这个代码的内容是:爬取虎牙直播,并获取主播人气排行(一直在变动,所以每个人的结果可能都不一样)ok,这就是我的完整代码。其中的一些操作我就不解释了,如果遇到问题,欢迎随时和我讨论。网络爬虫也叫网络蜘蛛,特指一类自动批量下载网络资源的程序,这是一个比较口语化的概念。接下来我来写一个原生爬虫,不高级,但是可以让大家理解爬虫的原理。网络爬虫的作用有很多,比如数据采集,搜索引擎,模拟操作。
Lua vs. Python:哪个更适合构建稳定可靠的长期运行爬虫? 2024-05-13 爬虫, python, lua, 开发语言 15人 已看 Lua是一种轻量级的脚本语言,具有快速、灵活、可嵌入等特点,常用于游戏开发、嵌入式系统和网络编程等领域。而Python是一种通用编程语言,具有简单易学、功能强大、社区活跃等优势,在Web开发、数据科学和人工智能等领域广泛应用。综上所述,Lua和Python在构建稳定可靠的长期运行爬虫方面各有优劣。Lua适合于对资源要求较高、快速启动和低资源占用的场景,但在功能和生态系统方面相对较弱;而Python则适合于构建大规模、稳定运行的爬虫应用,拥有丰富的生态系统和强大的数据处理能力。
爬虫基础(更适合于新手的爬虫认知) 2024-05-17 爬虫 16人 已看 URN与URL是URI的子集,在现行市场下,URN使用的非常少,几乎所有的URI都是URL,所以在不严谨的情况下,可以说URI就是URL。比如:打开一个浏览器,相当于就打开了一个浏览器进程,在浏览器上面播放视频,音乐,那么播放的视频和音乐就是这个浏览器进程上面的两个线程。b. 提取信息:对获取到的网页信息进行解析,提取需要的信息,常使用正则,Beautiful Soup,lxml,pyquery库完成。c. 保存数据:将提取到的信息,保存为TXT,JSON文本,数据库,HTML格式等。
python爬虫(五)之新出行汽车爬虫 2024-05-13 爬虫, 汽车 18人 已看 代码精选(www.codehuber.com),程序员的终身学习网站已上线!后端技术】、【前端领域】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【JavaGPT】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💝💝💝!
爬虫学习(2)破解百度翻译 2024-05-06 学习, 爬虫 13人 已看 方法来提取JSON格式的数据。这个方法会自动将JSON格式的响应内容转换为Python字典或列表,以便于在代码中进行处理。在百度翻译页面,右键选择“检查“,然后是Network,Fetch,如下图所示。是用于将HTTP响应体解析为JSON格式的方法。通常情况下,当你使用。库发送HTTP请求并得到响应后,可以使用。且返回的数据类型是json。1.找到要爬取的数据类型。
【爬虫】爬取股票历史K线数据写入数据库(三) 2024-05-09 爬虫, 数据库 31人 已看 1. 对东方财富官网进行分析,并作数据爬取,使用python,使用pip install requests 模拟http数据请求,获取数据。2. 将爬取的数据写入通过 sqlalchemy ORM 写入 sqlite数据库。3. 记录爬取股票的基本信息,如果库中已存在某个股票代码,则进行更新。4. 后续计划:会不断完善,最终目标是做出一个简单的股票查看客户端。5. 本系列所有源码均无偿分享,仅作交流无其他,供大家参考。
基于 Node.js 的爬虫库Puppeteer 2024-05-08 puppet, 爬虫, node.js 22人 已看 Puppeteer是一个基于Node.js的爬虫库,它提供了一个简单的API,可以让你使用Chrome浏览器的核心功能进行网络自动化操作,包括网页渲染、表单提交、点击按钮和执行JavaScript等。Puppeteer使用了Headless Chrome,它是Chrome浏览器的无头版本,可以在后台运行,并通过DevTools协议进行控制。使用Puppeteer可以实现模拟用户操作、抓取网站数据、生成PDF等功能。简单易用:Puppeteer提供了一个简单的API,可以方便地进行网页自动化操作。
【爬虫】爬取A股数据写入数据库(二) 2024-05-08 爬虫, 数据库 26人 已看 2024/05,本文主要内容如下:1. 对东方财富官网进行分析,并作数据爬取,使用python,使用pip install requests 模拟http数据请求,获取数据。2. 将爬取的数据写入通过 sqlalchemy ORM 写入 sqlite数据库。3. 记录爬取股票的基本信息,如果库中已存在某个股票代码,则进行更新。4. 后续计划:会不断完善,最终目标是做出一个简单的股票查看客户端。5. 本系列所有源码均无偿分享,仅作交流无其他,供大家参考。
Scala网络爬虫实战:抓取QQ音乐的音频资源 2024-05-08 爬虫, scala, 音视频, 后端, 开发语言 22人 已看 Scala是一种功能强大的多范式编程语言,结合了面向对象和函数式编程的特性。它具有优雅的语法、强大的类型系统和丰富的库支持,适用于各种应用场景,包括网络爬虫开发。面向对象和函数式编程:Scala既支持面向对象编程的特性,如类和对象,又支持函数式编程的特性,如高阶函数和不可变性。强大的类型系统:Scala的类型系统非常严格,可以帮助开发者在编译时捕获许多常见的错误,提高代码的稳定性和可靠性。并发编程模型:Scala提供了丰富的并发编程模型,如Actors和Futures,能够轻松处理大规模的并发任务。